
About Me
I'm a Ph.D. student in the NMS group of CSAIL at MIT, advised by Hari Balakrishnan. I studied Computer Science and Economics at the University of Maryland, College Park, where I worked closely with Dave Levin. At UMD I was also part of Gemstone Team TESLA, where I worked on wireless power transfer with Dr. Steven Anlage.
Publications
Privid: Practical, Privacy-Preserving Video Analytics Queries
Frank Cangialosi, Neil Agarwal, Venkat Arun, Junchen Jiang, Srinivas Narayana, Anand Sarwate, Ravi Netravali
USENIX NSDI '22 (Renton, WA)
PDF Code Talk Slides
Analytics on video recorded by cameras in public areas have the potential to fuel many exciting applications, but also pose the risk of intruding on individuals' privacy. Unfortunately, existing solutions fail to practically resolve this tension between utility and privacy, relying on perfect detection of all private information in each video frame--an elusive requirement. This paper presents: (1) a new notion of differential privacy (DP) for video analytics, (ρ,K,ϵ)-event-duration privacy, which protects all private information visible for less than a particular duration, rather than relying on perfect detections of that information, and (2) a practical system called Privid that enforces duration-based privacy even with the (untrusted) analyst-provided deep neural networks that are commonplace for video analytics today. Across a variety of videos and queries, we show that Privid achieves accuracies within 79-99% of a non-private system.
Reproducible Experiments for Internet Systems
Frank Cangialosi, Akshay Narayan
ACM P-RECS '22 (HPDC) (Minneapolis, MN)
PDF Code Talk (coming soon) We discuss our experience and recommendations as authors participating in the artifact evaluation (AE) process for systems conferences.
We discuss our experience and recommendations as authors participating in the artifact evaluation (AE) process for systems conferences.
Elasticity Detection: A Building Block for Delay-Sensitive Congestion Control
Prateesh Goyal, Akshay Narayan, Frank Cangialosi, Deepti Raghavan, Srinivas Narayana, Mohammad Alizadeh, Hari Balakrishnan
ACM SIGCOMM '22 (Amsterdam, Netherlands)
PDF Code 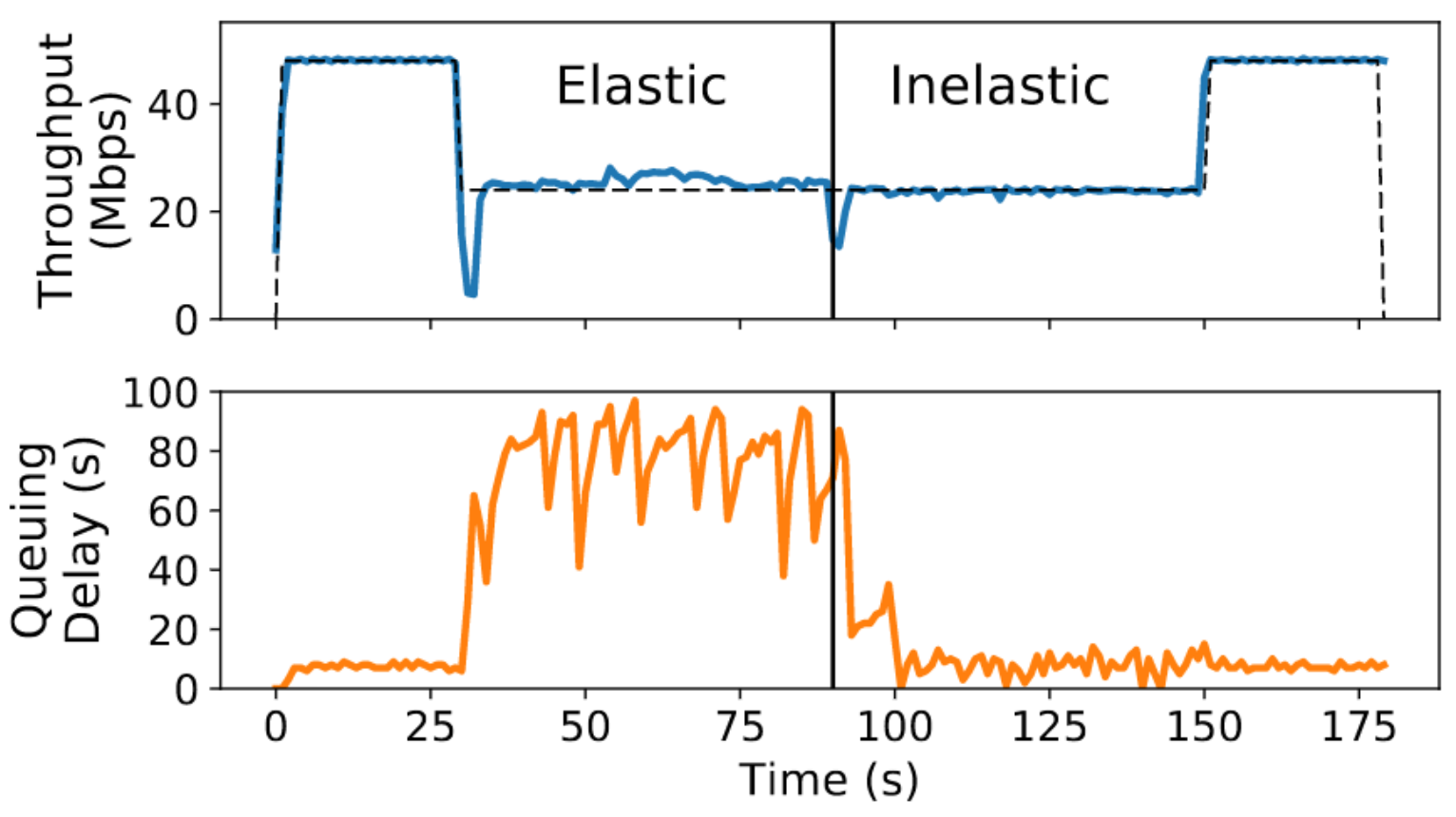 This paper develops a technique to detect whether the cross traffic competing with a flow is elastic or not, and shows how to use the elasticity detector to improve congestion control. If the cross traffic is elastic, i.e., made up of buffer-filling flows like Cubic or Reno, then one should use a scheme that competes well with such traffic. Such a scheme will not be able to control delays because the cross traffic will not cooperate. If, however, cross traffic is inelastic, then one can use a suitable delay-sensitive congestion control algorithm, which can control delays, but which would have obtained dismal throughput when run concurrently with a buffer-filling algorithm.
This paper develops a technique to detect whether the cross traffic competing with a flow is elastic or not, and shows how to use the elasticity detector to improve congestion control. If the cross traffic is elastic, i.e., made up of buffer-filling flows like Cubic or Reno, then one should use a scheme that competes well with such traffic. Such a scheme will not be able to control delays because the cross traffic will not cooperate. If, however, cross traffic is inelastic, then one can use a suitable delay-sensitive congestion control algorithm, which can control delays, but which would have obtained dismal throughput when run concurrently with a buffer-filling algorithm.
Site-to-Site Internet Traffic Control
Frank Cangialosi, Akshay Narayan, Prateesh Goyal, Radhika Mittal, Mohammad Alizadeh, Hari Balakrishnan
EuroSys '21 (Virtual)
Best Artifact Award
PDF Code Talk Slides 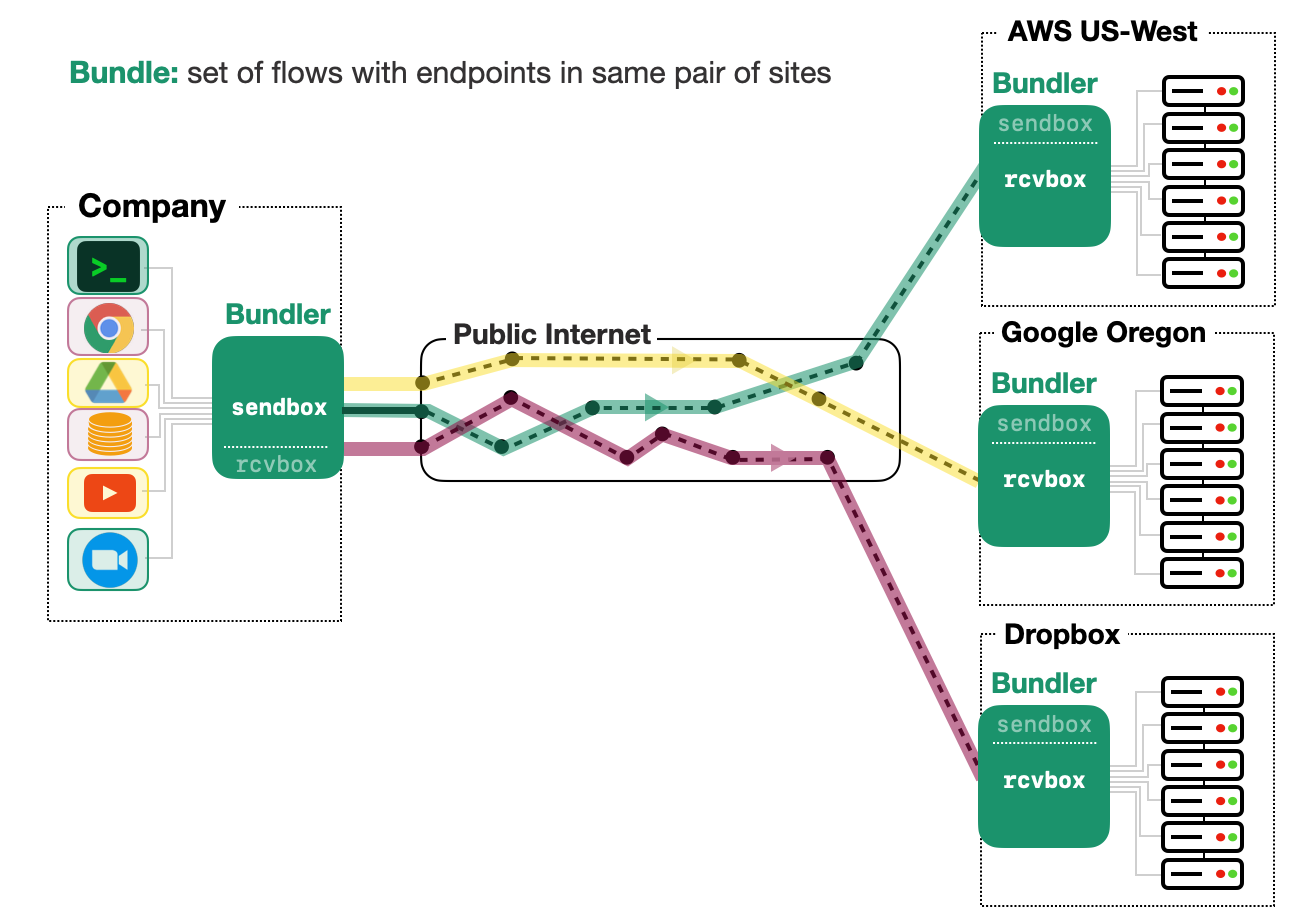 Queues allow network operators to control traffic: where queues build, they can enforce scheduling and shaping policies. In the Internet today, however, there is a mismatch between where queues build and where control is most effectively enforced; queues build at bottleneck links that are often not under the control of the data sender. To resolve this mismatch, we propose a new kind of middlebox, called Bundler. Bundler uses a novel inner control loop between a sendbox (in the sender's site) and a receivebox (in the receiver's site) to determine the aggregate rate for the bundle, leaving the end-to-end connections and their control loops intact. Enforcing this sending rate ensures that bottleneck queues that would have built up from the bundle's packets now shift from the bottleneck to the sendbox. The sendbox then exercises control over its traffic by scheduling packets to achieve higher-level objectives. We have implemented Bundler in Linux and evaluated it with real-world and emulation experiments.
Queues allow network operators to control traffic: where queues build, they can enforce scheduling and shaping policies. In the Internet today, however, there is a mismatch between where queues build and where control is most effectively enforced; queues build at bottleneck links that are often not under the control of the data sender. To resolve this mismatch, we propose a new kind of middlebox, called Bundler. Bundler uses a novel inner control loop between a sendbox (in the sender's site) and a receivebox (in the receiver's site) to determine the aggregate rate for the bundle, leaving the end-to-end connections and their control loops intact. Enforcing this sending rate ensures that bottleneck queues that would have built up from the bundle's packets now shift from the bottleneck to the sendbox. The sendbox then exercises control over its traffic by scheduling packets to achieve higher-level objectives. We have implemented Bundler in Linux and evaluated it with real-world and emulation experiments.
Park: An Open Platform for Learning-Augmented Computer Systems
Hongzi Mao, Parimarjan Negi, Akshay Narayan, Hanrui Wang, Jiacheng Yang, Haonan Wang, Ryan Marcus, Ravichandra Addanki, Mehrdad Khani Shirkoohi, Songtao He, Vikram Nathan, Frank Cangialosi, Shaileshh Venkatakrishnan, Wei-Hung Weng, Song Han, Tim Kraska, Mohammad Alizadeh
NeurIPS '19 (Vancouver, Canada)
PDF Code
Restructuring Endpoint Congestion Control
Akshay Narayan, Frank Cangialosi, Deepti Raghavan, Prateesh Goyal, Srinivas Narayana, Radhika Mittal, Mohammad Alizadeh, Hari Balakrishnan
SIGCOMM '18 (Budapest, Hungary)
PDF Code Talk Slides 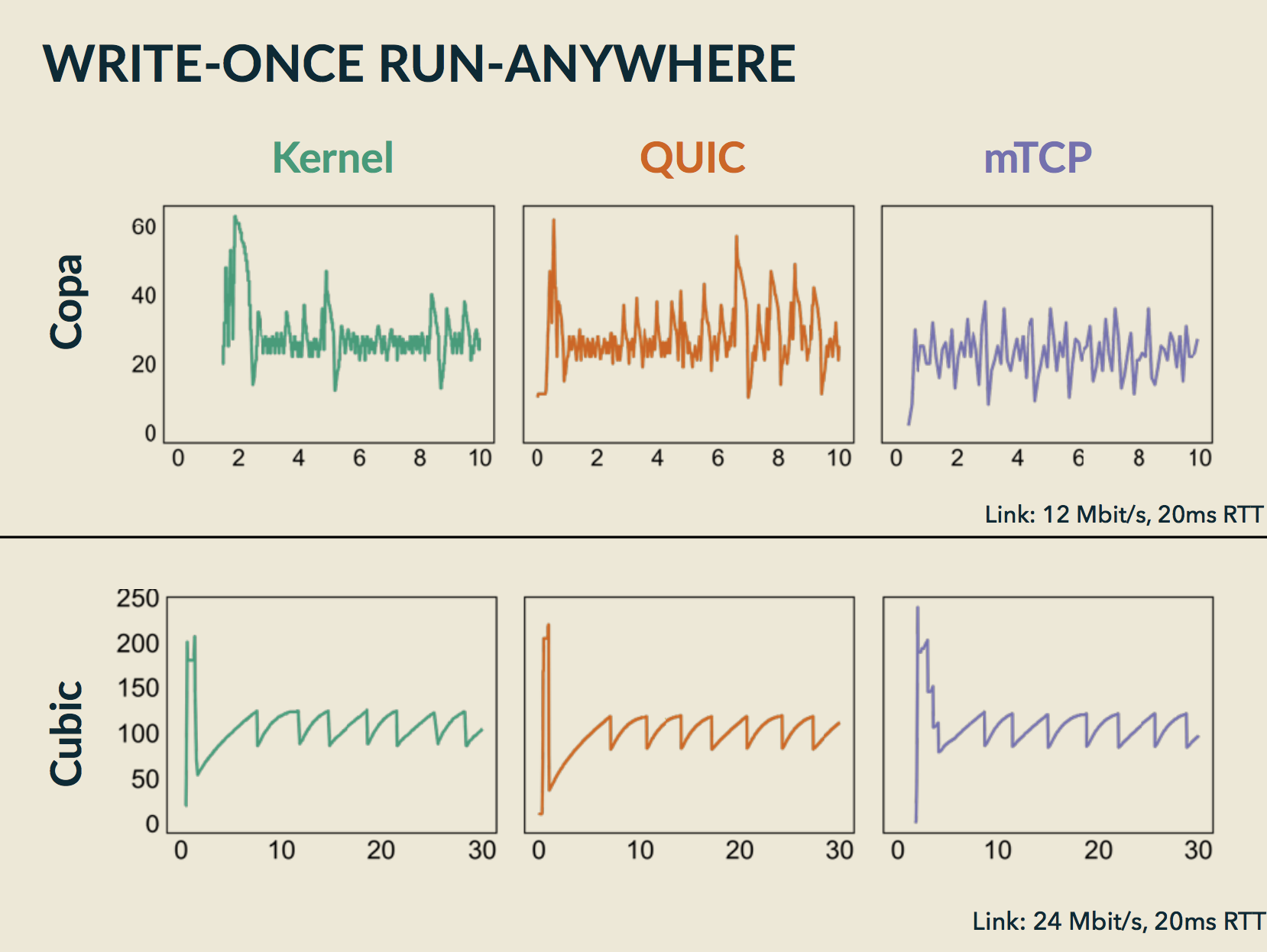 In this paper, we describe the design, implementation and evaluation of the Congestion Control Plane (CCP). CCP enables developers to write and test a single implementation of a congestion control algorithm and then run that sample implementation on any supported datapath (currently: the Linux Kernel, mTCP, Google's QUIC, and Meta's MVFST). These algorithms can be implemented in Rust or Python, and run in userspace, making them significantly easier to debug and improve. Our experiments show that CCP algorithms behave similarly to native implementations and incur only modest CPU overhead.
In this paper, we describe the design, implementation and evaluation of the Congestion Control Plane (CCP). CCP enables developers to write and test a single implementation of a congestion control algorithm and then run that sample implementation on any supported datapath (currently: the Linux Kernel, mTCP, Google's QUIC, and Meta's MVFST). These algorithms can be implemented in Rust or Python, and run in userspace, making them significantly easier to debug and improve. Our experiments show that CCP algorithms behave similarly to native implementations and incur only modest CPU overhead.
The Case for Moving Congestion Control Out of the Datapath
Akshay Narayan, Frank Cangialosi, Prateesh Goyal, Srinivas Narayana, Mohammad Alizadeh, Hari Balakrishnan
HotNets'17 (Palo Alto, California)
PDF Code Slides 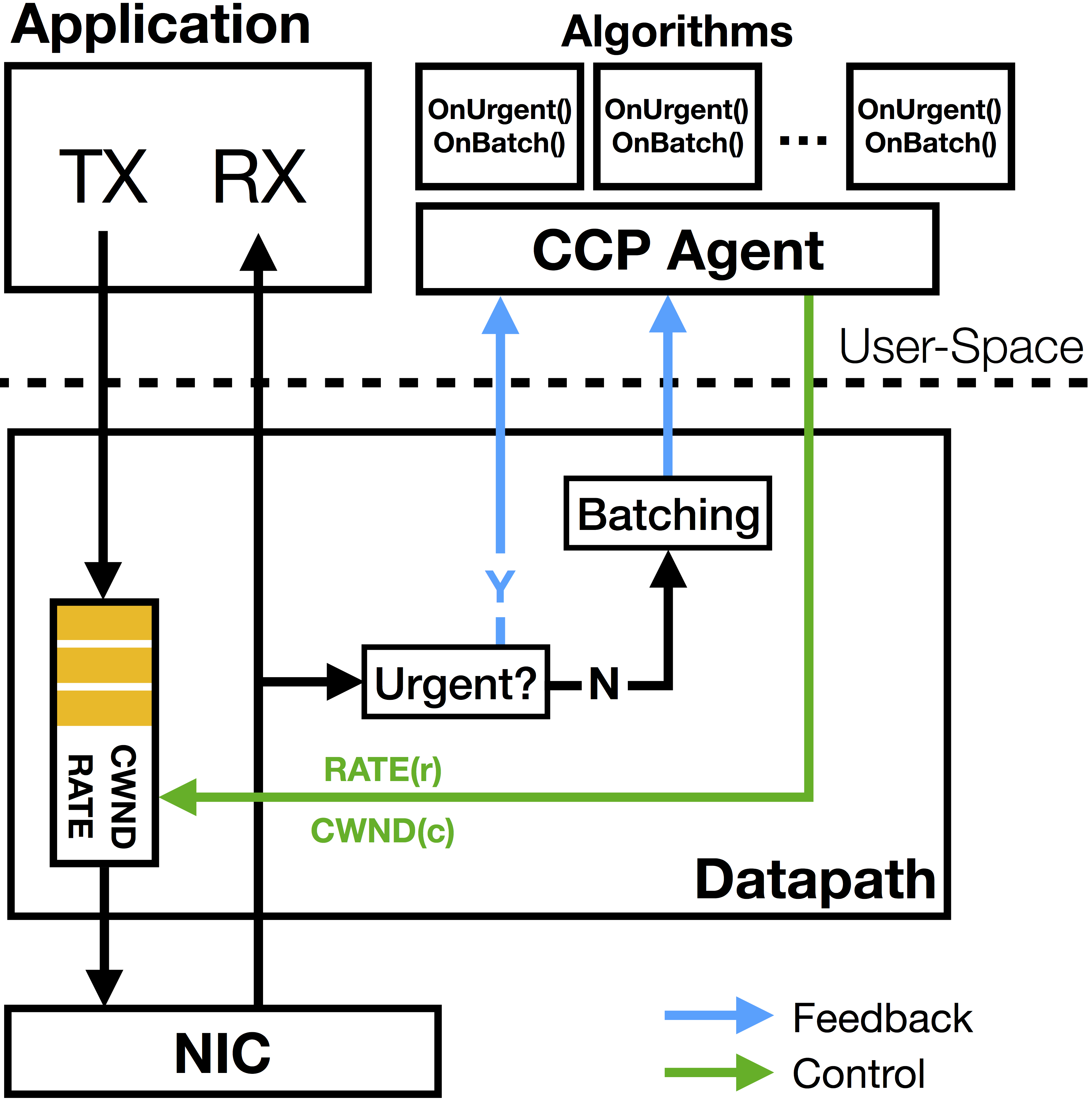 With Moore's law ending, the gap between general-purpose processor speeds and network link rates is widening. This trend has led to new packet-processing "datapaths" in endpoints, including kernel bypass software and emerging SmartNIC hardware. In addition, several applications are rolling out their own protocols atop UDP (e.g., QUIC, WebRTC, Mosh, etc.), forming new datapaths different from the traditional kernel TCP stack. All these datapaths require congestion control, but they must implement it anew because it is not possible to reuse the kernel TCP's implementations. This paper argues that congestion control must be removed from the datapath and moved into a separate user-space agent.
With Moore's law ending, the gap between general-purpose processor speeds and network link rates is widening. This trend has led to new packet-processing "datapaths" in endpoints, including kernel bypass software and emerging SmartNIC hardware. In addition, several applications are rolling out their own protocols atop UDP (e.g., QUIC, WebRTC, Mosh, etc.), forming new datapaths different from the traditional kernel TCP stack. All these datapaths require congestion control, but they must implement it anew because it is not possible to reuse the kernel TCP's implementations. This paper argues that congestion control must be removed from the datapath and moved into a separate user-space agent.
Measurement and Analysis of Private Key Sharing in the HTTPS Ecosystem
Frank Cangialosi, Taejoong Chung, David Choffnes, Dave Levin, Bruce Maggs, Alan Mislove, Christo Wilson
CCS'16 (ACM Conference on Computer and Communications Security) (Vienna, Austria)
PDF Code + Data Slides Poster (SoS'16)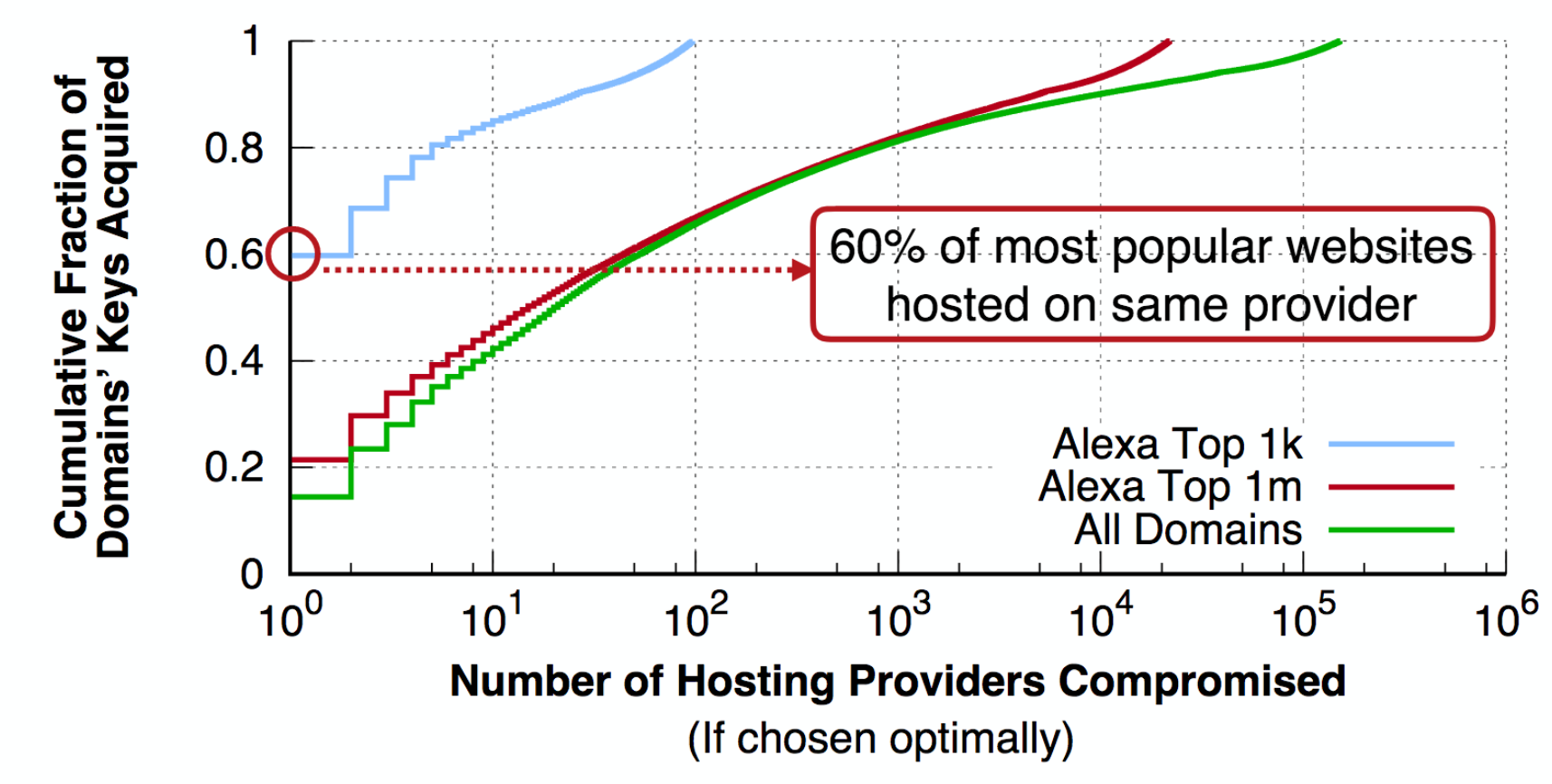 The semantics of authentication in the web's PKI are rather straightforward: if Alice has a certificate binding Bob's name to a public key, and if a remote entity can prove knowledge of Bob's private key, then (barring key compromise) that remote entity must be Bob. However, in reality, many websites-and the majority of the most popular ones-are hosted at least in part by third-parties such as Content Distribution Networks (CDNs) or web hosting providers. Put simply: administrators of websites who deal with critically sensitive user data are giving their private keys to thirdparties. Critically, this sharing of keys is undetectable by most users, and widely unknown even among researchers. In this paper, we perform a large-scale measurement study of administrators' decisions regarding key sharing with third-party hosting providers and the impact this sharing has on key management. We analyze the prevalence with which websites trust third-party hosting providers with their secret keys, as well as the impact that this trust has on responsible key management practices, such as revocation.
The semantics of authentication in the web's PKI are rather straightforward: if Alice has a certificate binding Bob's name to a public key, and if a remote entity can prove knowledge of Bob's private key, then (barring key compromise) that remote entity must be Bob. However, in reality, many websites-and the majority of the most popular ones-are hosted at least in part by third-parties such as Content Distribution Networks (CDNs) or web hosting providers. Put simply: administrators of websites who deal with critically sensitive user data are giving their private keys to thirdparties. Critically, this sharing of keys is undetectable by most users, and widely unknown even among researchers. In this paper, we perform a large-scale measurement study of administrators' decisions regarding key sharing with third-party hosting providers and the impact this sharing has on key management. We analyze the prevalence with which websites trust third-party hosting providers with their secret keys, as well as the impact that this trust has on responsible key management practices, such as revocation.
Time Reversed EM Wave Propagation as a Novel Method of Wireless Power Transfer
Frank Cangialosi, Tyler Grover, Patrick Healey, Tim Furman, Andrew Simon, Steven Anlage
WPTC'16 (IEEE Wireless Power Transfer Conference) (Aveiro, Portugal)
Best Paper Award
UMD OTC Invention of The Year 2016
PDF Project Slides Poster (WPTC'16)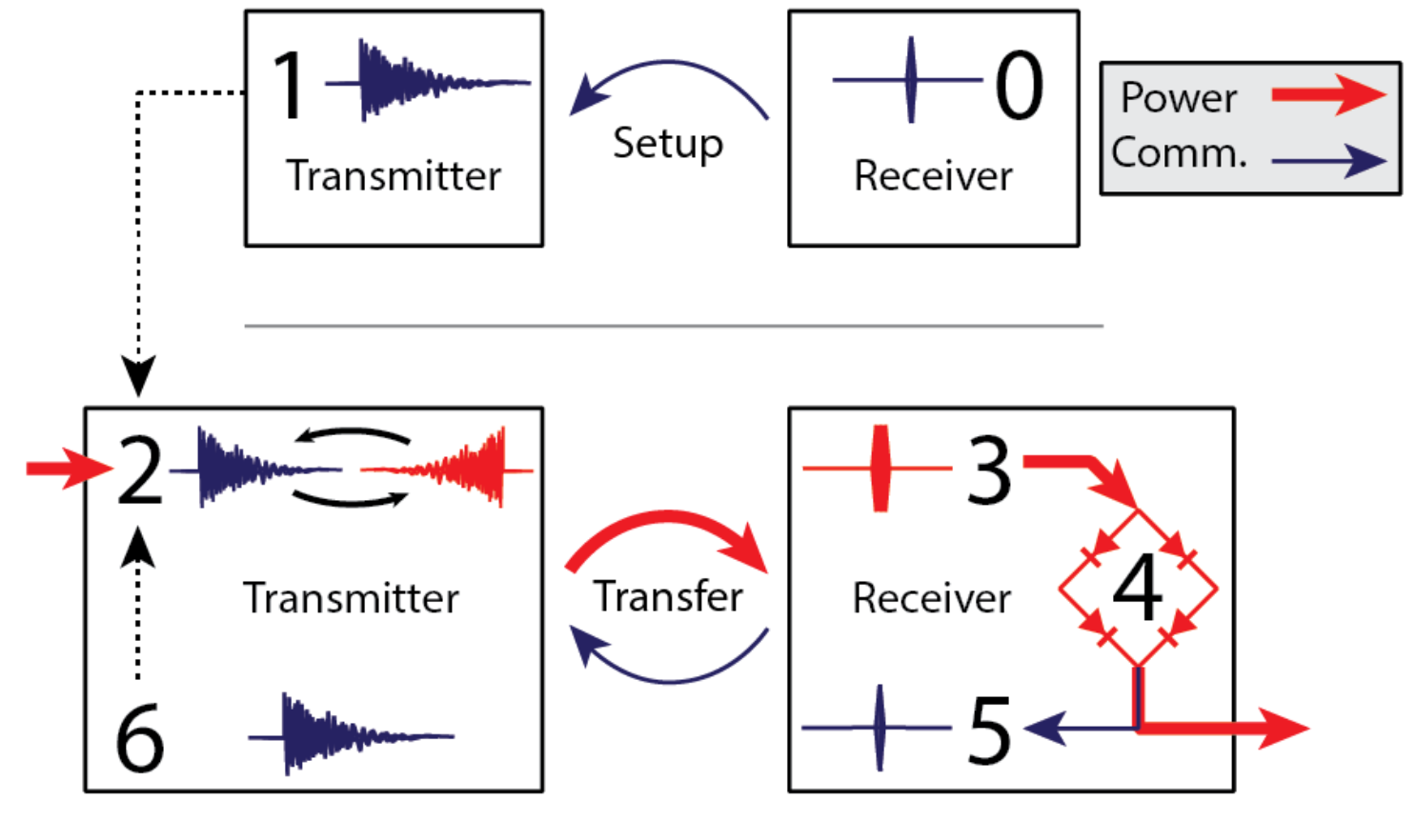 We investigate the application of time reversed electromagnetic wave propagation to transmit energy to a moving target in a reverberant environment. "Time reversal" is a signal focusing method that exploits the time reversal invariance of the lossless wave equation to focus signals on a small region inside a complex scattering environment. In this work, we explore the properties of time reversed microwave pulses in a low-loss raychaotic chamber. We measure the spatial profile of the collapsing wavefront around the target antenna, and demonstrate that time reversal can be used to transfer energy to a receiver in motion. We discuss the results of these experiments, and explore their implications for a wireless power transmission system based on time reversal.
We investigate the application of time reversed electromagnetic wave propagation to transmit energy to a moving target in a reverberant environment. "Time reversal" is a signal focusing method that exploits the time reversal invariance of the lossless wave equation to focus signals on a small region inside a complex scattering environment. In this work, we explore the properties of time reversed microwave pulses in a low-loss raychaotic chamber. We measure the spatial profile of the collapsing wavefront around the target antenna, and demonstrate that time reversal can be used to transfer energy to a receiver in motion. We discuss the results of these experiments, and explore their implications for a wireless power transmission system based on time reversal.
Picocenter: Supporting Long-Lived, Mostly-Idle Applications in Cloud Environments
Liang Zhang, James Litton, Frank Cangialosi, Theophilus Benson, Dave Levin, Alan Mislove
EuroSys'16 (European Conference on Computer Systems) (London, UK)
PDF Code Slides Poster (SOCC'15)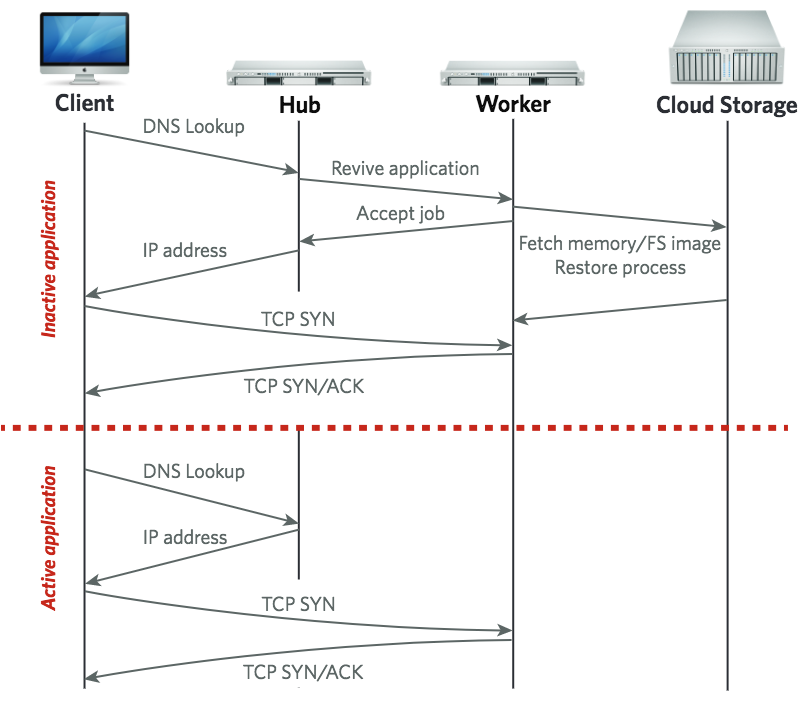 Cloud computing has evolved to meet user demands, from arbitrary VMs offered by IaaS to the narrow application interfaces of PaaS. Unfortunately, there exists an intermediate point that is not well met by today's offerings: users who wish to run arbitrary, already available binaries (as opposed to rewriting their own application for a PaaS) yet expect their applications to be long-lived but mostly idle (as opposed to the always-on VM of IaaS). For example, end users who wish to run their own email or DNS server. In this paper, we explore an alternative approach for cloud computation based on a process-like abstraction rather than a virtual machine abstraction, thereby gaining the scalability and efficiency of PaaS along with the generality of IaaS.
Cloud computing has evolved to meet user demands, from arbitrary VMs offered by IaaS to the narrow application interfaces of PaaS. Unfortunately, there exists an intermediate point that is not well met by today's offerings: users who wish to run arbitrary, already available binaries (as opposed to rewriting their own application for a PaaS) yet expect their applications to be long-lived but mostly idle (as opposed to the always-on VM of IaaS). For example, end users who wish to run their own email or DNS server. In this paper, we explore an alternative approach for cloud computation based on a process-like abstraction rather than a virtual machine abstraction, thereby gaining the scalability and efficiency of PaaS along with the generality of IaaS.
Ting: Measuring and Exploiting Latencies Between All Tor Nodes
Frank Cangialosi, Dave Levin, Neil Spring
IMC'15 (Internet Measurement Conference) (Tokyo, Japan)
PDF Code + Data Slides 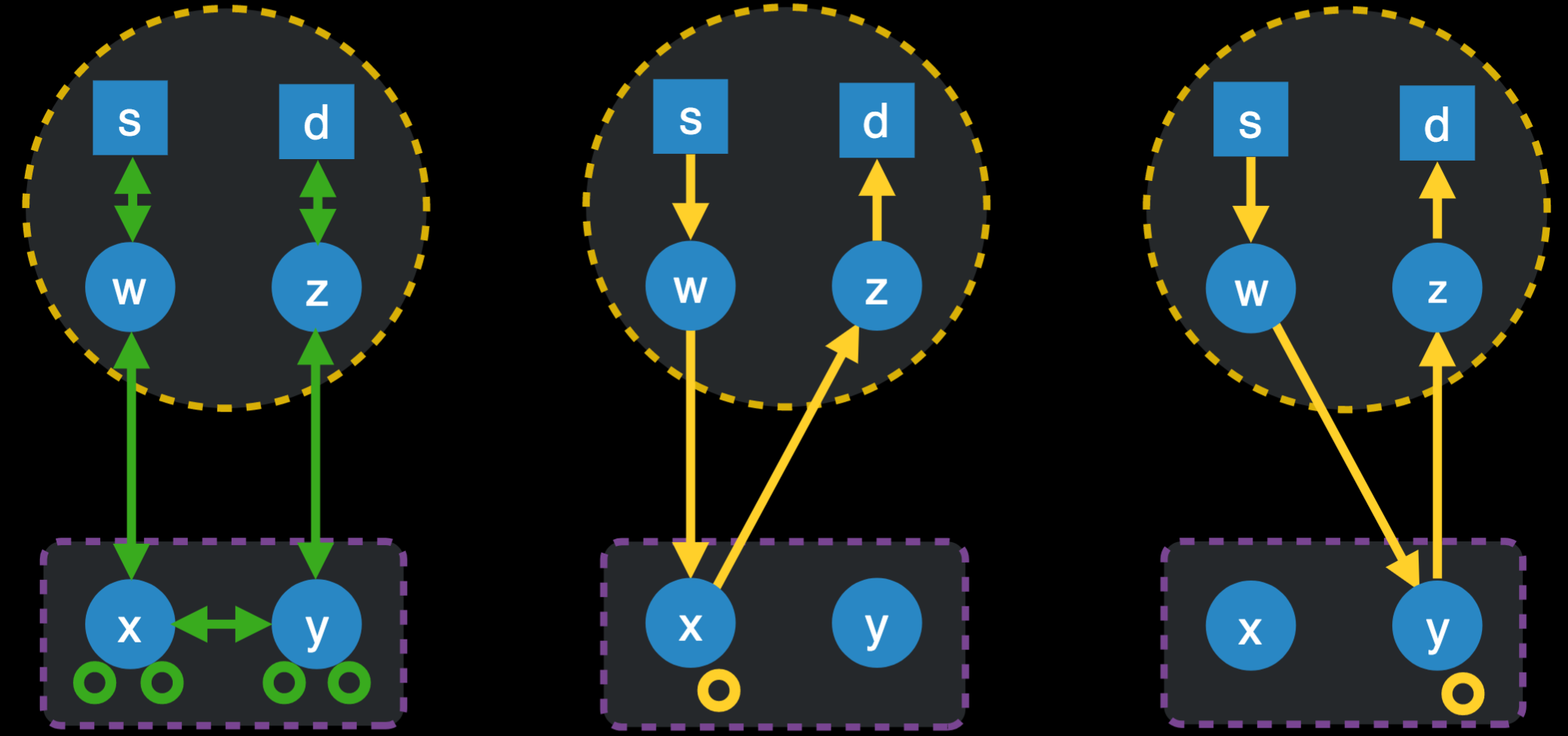 Tor is a peer-to-peer overlay routing network that achieves unlinkable communication between source and destination. Unlike traditional mix-nets, Tor seeks to balance anonymity and performance, particularly with respect to providing lowlatency communication. As a result, understanding the latencies between peers in the Tor network could be an extremely powerful tool in understanding and improving Tor's performance and anonymity properties. Unfortunately, there are no practical techniques for inferring accurate latencies between two arbitrary hosts on the Internet, and Tor clients are not instrumented to collect and report on these measurements. In this paper, we present Ting, a technique for measuring latencies between arbitrary Tor nodes from a single vantage point.
Tor is a peer-to-peer overlay routing network that achieves unlinkable communication between source and destination. Unlike traditional mix-nets, Tor seeks to balance anonymity and performance, particularly with respect to providing lowlatency communication. As a result, understanding the latencies between peers in the Tor network could be an extremely powerful tool in understanding and improving Tor's performance and anonymity properties. Unfortunately, there are no practical techniques for inferring accurate latencies between two arbitrary hosts on the Internet, and Tor clients are not instrumented to collect and report on these measurements. In this paper, we present Ting, a technique for measuring latencies between arbitrary Tor nodes from a single vantage point.
Projects
Strongly Polynomial Algorithms for Generalized Flow Maximization
Frank Cangialosi, Katie Lewis, David Palmer
PDF 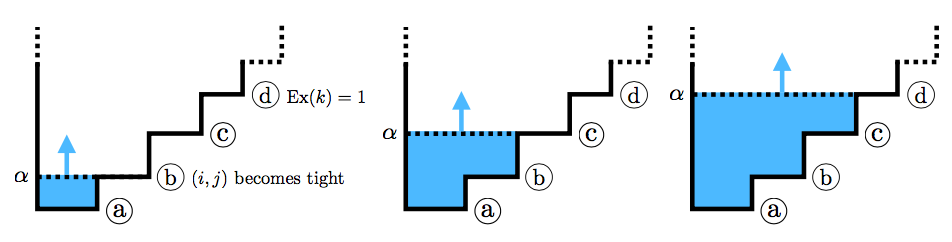 Let G = (V, E) be a graph. In the generalized maximum flow problem–as in the ordinary maximum flow problem–the aim is to maximize the total flow delivered to a sink node t ∈ V . The difference is that in the generalized problem, each edge e is endowed with a gain factor ɣe > 0, which scales the flow passing through that edge. Gains might, for example, represent exchange rates between currencies or dissipation rates of a physical quantity. Setting ɣe ≡ 1 recovers the ordinary maximum flow problem. Until recently, the best known algorithms were all weakly polynomial. In 2013, Végh developed the first strongly polynomial algorithm. In 2017, Olver and Végh built on this work and developed an algorithm that is faster than Végh's original algorithm by a factor of almost O(n²), resulting in a running time that is as fast as the best weakly polynomial algorithms even for small parameter values. In this paper, we aim to familiarize the reader with recent algorithmic developments on the generalized maximum flow problem and to build intuition for the techniques used to achieve a strongly polynomial result.
Let G = (V, E) be a graph. In the generalized maximum flow problem–as in the ordinary maximum flow problem–the aim is to maximize the total flow delivered to a sink node t ∈ V . The difference is that in the generalized problem, each edge e is endowed with a gain factor ɣe > 0, which scales the flow passing through that edge. Gains might, for example, represent exchange rates between currencies or dissipation rates of a physical quantity. Setting ɣe ≡ 1 recovers the ordinary maximum flow problem. Until recently, the best known algorithms were all weakly polynomial. In 2013, Végh developed the first strongly polynomial algorithm. In 2017, Olver and Végh built on this work and developed an algorithm that is faster than Végh's original algorithm by a factor of almost O(n²), resulting in a running time that is as fast as the best weakly polynomial algorithms even for small parameter values. In this paper, we aim to familiarize the reader with recent algorithmic developments on the generalized maximum flow problem and to build intuition for the techniques used to achieve a strongly polynomial result.