 |
Michael (Miki) Rubinstein
Principal Scientist / Director, Google DeepMind, Cambridge MA Email: mrubxkxkxk@google.com | mrubqwqwqw@csail.mit.edu Google Scholar | LinkedIn |
I am a Research Scientist at Google. I received my PhD from MIT, under the supervision of Bill Freeman. Before joining Google, I spent a year as a postdoc at Microsoft Research New England.
I work at the intersection
of computer vision and computer graphics. In particular I am interested in low-level
image/video processing and computational photography. You can read more about my research here.
| Current/Past Affiliations: | |
 |
|
|
 |
 |
Academic Activities, Awards
Research Highlights
 |
 |
|
DreamBooth |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Video Magnification, Analysis of Small Motions In my PhD I developed new methods to extract
subtle motion and color signals from videos. These methods
can be used to visualize blood perfusion, measure heart rate, and magnify
tiny motions and changes we cannot normally see, all using regular
cameras and videos.TEDx talk (Nov'14) | My
PhD thesis (MIT Feb'14) | Story
in NYTimes (Feb'13) | Revealing
Invisible Changes in the World (NSF SciVis'12) | Phase-based
Motion Processing (SIGGRAPH'13) | Eulerian
Video Magnification (SIGGRAPH'12) | Motion
Denoising (CVPR'11) |
 |
|
| Pattern Discovery and Joint Inteference in Image CollectionsDense image correspondences are used to propagate information across weakly-annotated image datasets, to infer pixel labels jointly in all the images.Tutorial talk (ICCV'13) | Object Discovery and Segmentation (CVPR'13) | Annotation Propagation (ECCV'12) |  |
|
| Image and Video Retargeting In my Masters I worked on content-aware
algorithms for resizing images and videos to fit different display sizes
and aspect ratios. "Content-aware" means the image/video is resized
based on its actual content: parts that are visually more important
are preserved at the expense of less important ones. This technology was licensed by Adobe and added to Photoshop as "Content Aware Scaling".RetargetMe dataset (SIGGRAPH Asia'10) | My Masters thesis (May'09) | Multi-operator Retargeting (SIGGRAPH'09) | Improved Seam-Carving (SIGGRAPH'08) |
 |
Publications
My publications and patents on Google Scholar
 |
Luming Tang, Nataniel Ruiz, Qinghao Chu, Yuanzhen Li, Aleksander Holynski, David E. Jacobs, Bharath Hariharan, Yael Pritch, Neal Wadhwa, Kfir Aberman, Michael Rubinstein RealFill: Reference-Driven Generation for Authentic Image Completion arXiv, 2023 Abstract | Paper | Webpage Recent advances in generative imagery have brought forth outpainting and inpainting models that can produce high-quality, plausible image content in unknown regions, but the content these models hallucinate is necessarily inauthentic, since the models lack sufficient context about the true scene. In this work, we propose RealFill, a novel generative approach for image completion that fills in missing regions of an image with the content that should have been there. RealFill is a generative inpainting model that is personalized using only a few reference images of a scene. These reference images do not have to be aligned with the target image, and can be taken with drastically varying viewpoints, lighting conditions, camera apertures, or image styles. Once personalized, RealFill is able to complete a target image with visually compelling contents that are faithful to the original scene. We evaluate RealFill on a new image completion benchmark that covers a set of diverse and challenging scenarios, and find that it outperforms existing approaches by a large margin. |
|
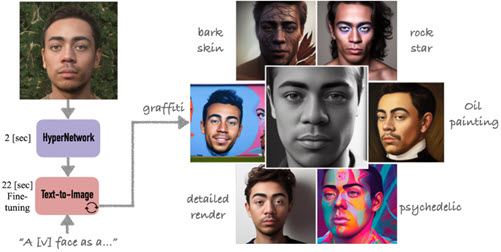 |
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Wei Wei, Tingbo Hou, Yael Pritch, Neal Wadhwa, Michael Rubinstein, Kfir Aberman Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models arXiv, 2023 Abstract | Paper | Webpage Personalization has emerged as a prominent aspect within the field of generative AI, enabling the synthesis of individuals in diverse contexts and styles, while retaining high-fidelity to their identities. However, the process of personalization presents inherent challenges in terms of time and memory requirements. Fine-tuning each personalized model needs considerable GPU time investment, and storing a personalized model per subject can be demanding in terms of storage capacity. To overcome these challenges, we propose HyperDreamBooth - a hypernetwork capable of efficiently generating a small set of personalized weights from a single image of a person. By composing these weights into the diffusion model, coupled with fast finetuning, HyperDreamBooth can generate a person's face in various contexts and styles, with high subject details while also preserving the model's crucial knowledge of diverse styles and semantic modifications. Our method achieves personalization on faces in roughly 20 seconds, 25x faster than DreamBooth and 125x faster than Textual Inversion, using as few as one reference image, with the same quality and style diversity as DreamBooth. Also our method yields a model that is 10000x smaller than a normal DreamBooth model. |
|
 |
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang, Glenn Entis, Yuanzhen Li, Yuan Hao, Irfan Essa, Michael Rubinstein, Dilip Krishnan StyleDrop: Text-To-Image Generation in Any Style Conf. on Neural Information Processing Systems (NeurIPS), 2023 Abstract | Paper | Webpage We present StyleDrop that enables the generation of images that faithfully follow a specific style, powered by Muse, a text-to-image generative vision transformer. StyleDrop is extremely versatile and captures nuances and details of a user-provided style, such as color schemes, shading, design patterns, and local and global effects. StyleDrop works by efficiently learning a new style by fine-tuning very few trainable parameters (less than 1% of total model parameters), and improving the quality via iterative training with either human or automated feedback. Better yet, StyleDrop is able to deliver impressive results even when the user supplies only a single image specifying the desired style. An extensive study shows that, for the task of style tuning text-to-image models, Styledrop on Muse convincingly outperforms other methods, including DreamBooth and Textual Inversion on Imagen or Stable Diffusion. |
|
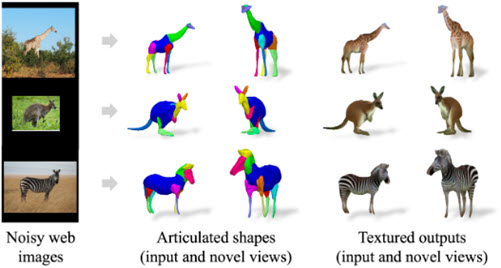 |
Chun-Han Yao, Amit Raj, Wei-Chih Hung, Yuanzhen Li, Michael Rubinstein, Ming-Hsuan Yang, Varun Jampani ARTIC3D: Learning Robust Articulated 3D Shapes from Noisy Web Image Collections Conf. on Neural Information Processing Systems (NeurIPS), 2023 Abstract | Paper | Video | Webpage Estimating 3D articulated shapes like animal bodies from monocular images is inherently challenging due to the ambiguities of camera viewpoint, pose, texture, lighting, etc. We propose ARTIC3D, a self-supervised framework to reconstruct per-instance 3D shapes from a sparse image collection in-the-wild. Specifically, ARTIC3D is built upon a skeleton-based surface representation and is further guided by 2D diffusion priors from Stable Diffusion. First, we enhance the input images with occlusions/truncation via 2D diffusion to obtain cleaner mask estimates and semantic features. Second, we perform diffusion-guided 3D optimization to estimate shape and texture that are of high-fidelity and faithful to input images. We also propose a novel technique to calculate more stable image-level gradients via diffusion models compared to existing alternatives. Finally, we produce realistic animations by fine-tuning the rendered shape and texture under rigid part transformations. Extensive evaluations on multiple existing datasets as well as newly introduced noisy web image collections with occlusions and truncation demonstrate that ARTIC3D outputs are more robust to noisy images, higher quality in terms of shape and texture details, and more realistic when animated. |
|
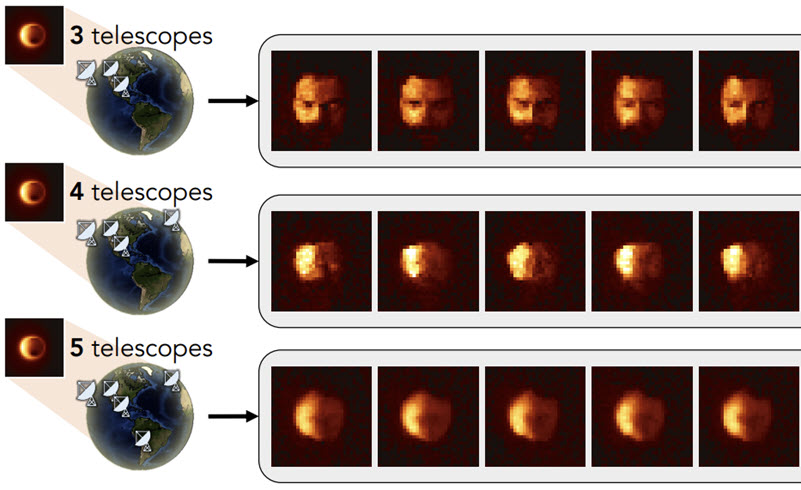 |
Berthy T. Feng, Jamie Smith, Michael Rubinstein, Huiwen Chang, Katherine L. Bouman, William T. Freeman Score-Based Diffusion Models as Principled Priors for Inverse Imaging IEEE/CVF International Conference on Computer Vision (ICCV), 2023 Abstract | Paper | Webpage It is important in computational imaging to understand the uncertainty of images reconstructed from imperfect measurements. We propose turning score-based diffusion models into principled priors (``score-based priors'') for analyzing a posterior of images given measurements. Previously, probabilistic priors were limited to handcrafted regularizers and simple distributions. In this work, we empirically validate the theoretically-proven probability function of a score-based diffusion model. We show how to sample from resulting posteriors by using this probability function for variational inference. Our results, including experiments on denoising, deblurring, and interferometric imaging, suggest that score-based priors enable principled inference with a sophisticated, data-driven image prior. |
|
 |
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan Barron, Yuanzhen Li, Varun Jampani DreamBooth3D: Subject-Driven Text-to-3D Generation IEEE/CVF International Conference on Computer Vision (ICCV), 2023 Abstract | Paper | Video | Webpage We present DreamBooth3D, an approach to personalize text-to-3D generative models from as few as 3-6 casually captured images of a subject. Our approach combines recent advances in personalizing text-to-image models (DreamBooth) with text-to-3D generation (DreamFusion). We find that naively combining these methods fails to yield satisfactory subject-specific 3D assets due to personalized text-to-image models overfitting to the input viewpoints of the subject. We overcome this through a 3-stage optimization strategy where we jointly leverage the 3D consistency of neural radiance fields together with the personalization capability of text-to-image models. Our method can produce high-quality, subject-specific 3D assets with text-driven modifications such as novel poses, colors and attributes that are not seen in any of the input images of the subject. |
|
|
Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T. Freeman, Michael Rubinstein, Yuanzhen Li, Dilip Krishnan Muse: Text-To-Image Generation via Masked Generative Transformers International Conference on Machine Learning (ICML), 2023 Abstract | Paper | Webpage We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing.
|
|
 |
Chun-Han Yao, Wei-Chih Hung, Yuanzhen Li, Michael Rubinstein, Ming-Hsuan Yang, Varun Jampani Hi-LASSIE: High-Fidelity Articulated Shape and Skeleton Discovery from Sparse Image Ensemble IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2023 Abstract | Paper | Webpage Automatically estimating 3D skeleton, shape, camera viewpoints, and part articulation from sparse in-the-wild image ensembles is a severely under-constrained and challenging problem. Most prior methods rely on large-scale image datasets, dense temporal correspondence, or human annotations like camera pose, 2D keypoints, and shape templates. We propose Hi-LASSIE, which performs 3D articulated reconstruction from only 20-30 online images in the wild without any user-defined shape or skeleton templates. We follow the recent work of LASSIE that tackles a similar problem setting and make two significant advances. First, instead of relying on a manually annotated 3D skeleton, we automatically estimate a class-specific skeleton from the selected reference image. Second, we improve the shape reconstructions with novel instance-specific optimization strategies that allow reconstructions to faithful fit on each instance while preserving the class-specific priors learned across all images. Experiments on in-the-wild image ensembles show that Hi-LASSIE obtains higher fidelity state-of-the-art 3D reconstructions despite requiring minimum user input. |
|
| |
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2023 Abstract | Paper | Webpage | Code (by others) Best Student Paper Honorable Mention Large text-to-image models achieved a remarkable leap in the evolution of AI, enabling high-quality and diverse synthesis of images from a given text prompt. However, these models lack the ability to mimic the appearance of subjects in a given reference set and synthesize novel renditions of them in different contexts. In this work, we present a new approach for ``personalization'' of text-to-image diffusion models (specializing them to users' needs). Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model (Imagen, although our method is not limited to a specific model) such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images. We apply our technique to several previously-unassailable tasks, including subject recontextualization, text-guided view synthesis, appearance modification, and artistic rendering (all while preserving the subject's key features). |
|
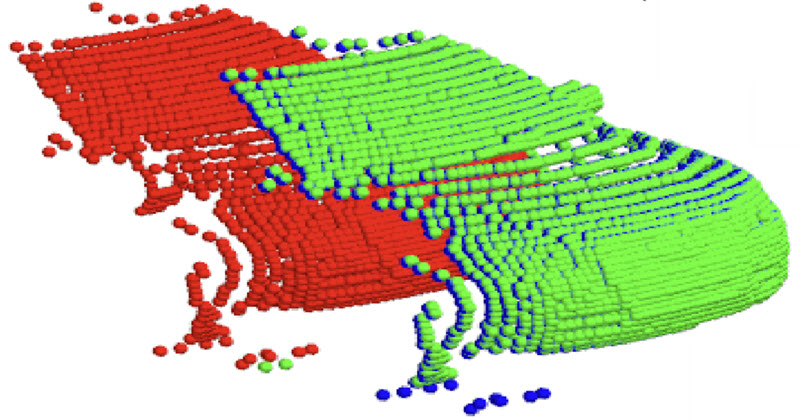 |
Itai Lang, Dror Aiger, Forrester Cole, Shai Avidan, Michael Rubinstein SCOOP: Self-Supervised Correspondence and Optimization-Based Scene Flow IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2023 Abstract | Paper | Webpage | Video Scene flow estimation is a long-standing problem in computer vision, where the goal is to find the 3D motion of a scene from its consecutive observations. Recently, there have been efforts to compute the scene flow from 3D point clouds. A common approach is to train a regression model that consumes source and target point clouds and outputs the per-point translation vector. An alternative is to learn point matches between the point clouds concurrently with regressing a refinement of the initial correspondence flow. In both cases, the learning task is very challenging since the flow regression is done in the free 3D space, and a typical solution is to resort to a large annotated synthetic dataset. We introduce SCOOP, a new method for scene flow estimation that can be learned on a small amount of data without employing ground-truth flow supervision. In contrast to previous work, we train a pure correspondence model focused on learning point feature representation and initialize the flow as the difference between a source point and its softly corresponding target point. Then, in the run-time phase, we directly optimize a flow refinement component with a self-supervised objective, which leads to a coherent and accurate flow field between the point clouds. Experiments on widespread datasets demonstrate the performance gains achieved by our method compared to existing leading techniques while using a fraction of the training data. Our code is publicly available at this https URL. |
|
 |
Erika Lu, Forrester Cole, Weidi Xie, Tali Dekel, William T. Freeman, Andrew Zisserman, Michael Rubinstein Associating Objects and Their Effects in Video Through Coordination Games Conf. on Neural Information Processing Systems (NeurIPS), 2022 Abstract | Paper | Webpage We explore a feed-forward approach for decomposing a video into layers, where each layer contains an object of interest along with its associated shadows, reflections, and other visual effects. This problem is challenging since associated effects vary widely with the 3D geometry and lighting conditions in the scene, and ground-truth labels for visual effects are difficult (and in some cases impractical) to collect. We take a self-supervised approach and train a neural network to produce a foreground image and alpha matte from a rough object segmentation mask under a reconstruction and sparsity loss. Under reconstruction loss, the layer decomposition problem is underdetermined: many combinations of layers may reconstruct the input video. Inspired by the game theory concept of focal points—or Schelling points—we pose the problem as a coordination game, where each player (network) predicts the effects for a single object without knowledge of the other players' choices. The players learn to converge on the "natural" layer decomposition in order to maximize the likelihood of their choices aligning with the other players'. We train the network to play this game with itself, and show how to design the rules of this game so that the focal point lies at the correct layer decomposition. We demonstrate feed-forward results on a challenging synthetic dataset, then show that pretraining on this dataset significantly reduces optimization time for real videos. |
|
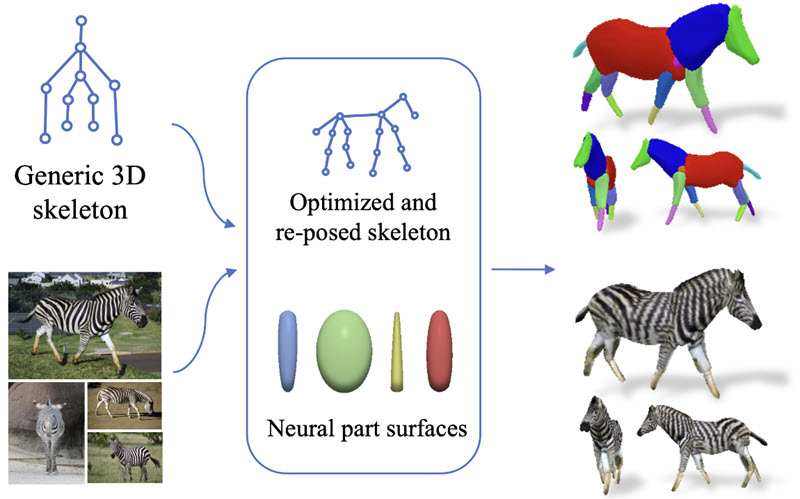 |
Chun-Han Yao, Wei-Chih Hung, Yuanzhen Li, Michael Rubinstein, Ming-Hsuan Yang, Varun Jampani LASSIE: Learning Articulated Shape from Sparse Image Ensemble via 3D Part Discovery Conf. on Neural Information Processing Systems (NeurIPS), 2022 Abstract | Paper | Webpage Creating high-quality articulated 3D models of animals is challenging either via manual creation or using 3D scanning tools. Therefore, techniques to reconstruct articulated 3D objects from 2D images are crucial and highly useful. In this work, we propose a practical problem setting to estimate 3D pose and shape of animals given only a few (10-30) in-the-wild images of a particular animal species (say, horse). Contrary to existing works that rely on pre-defined template shapes, we do not assume any form of 2D or 3D ground-truth annotations, nor do we leverage any multi-view or temporal information. Moreover, each input image ensemble can contain animal instances with varying poses, backgrounds, illuminations, and textures. Our key insight is that 3D parts have much simpler shape compared to the overall animal and that they are robust w.r.t. animal pose articulations. Following these insights, we propose LASSIE, a novel optimization framework which discovers 3D parts in a self-supervised manner with minimal user intervention. A key driving force behind LASSIE is the enforcing of 2D-3D part consistency using self-supervisory deep features. Experiments on Pascal-Part and self-collected in-the-wild animal datasets demonstrate considerably better 3D reconstructions as well as both 2D and 3D part discovery compared to prior arts. |
|
 |
Deqing Sun, Charles Herrmann, Fitsum Reda, Michael Rubinstein, David Fleet, William T Freeman Disentangling Architecture and Training for Optical Flow Proc. of the European Conference on Computer Vision (ECCV), 2022 Abstract | Paper | Webpage | Code How important are training details and datasets to recent optical flow models like RAFT? And do they generalize? To explore these questions, rather than develop a new model, we revisit three prominent models, PWC-Net, IRR-PWC and RAFT, with a common set of modern training techniques and datasets, and observe significant performance gains, demonstrating the importance and generality of these training details. Our newly trained PWC-Net and IRR-PWC models show surprisingly large improvements, up to 30% versus original published results on Sintel and KITTI 2015 benchmarks. They outperform the more recent Flow1D on KITTI 2015 while being 3× faster during inference. Our newly trained RAFT achieves an Fl-all score of 4.31% on KITTI 2015, more accurate than all published optical flow methods at the time of writing. Our results demonstrate the benefits of separating the contributions of models, training techniques and datasets when analyzing performance gains of optical flow methods. Our source code will be publicly available. |
|
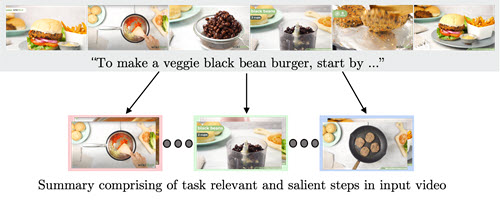 |
Medhini Narasimhan, Arsha Nagrani, Chen Sun, Michael Rubinstein, Trevor Darrell, Anna Rohrbach, Cordelia Schmid TL;DW? Summarizing Instructional Videos with Task Relevance & Cross-Modal Saliency Proc. of the European Conference on Computer Vision (ECCV), 2022 Abstract | Paper | Webpage | Code YouTube users looking for instructions for a specific task may spend a long time browsing content trying to find the right video that matches their needs. Creating a visual summary (abridged version of a video) provides viewers with a quick overview and massively reduces search time. In this work, we focus on summarizing instructional videos, an under-explored area of video summarization. In comparison to generic videos, instructional videos can be parsed into semantically meaningful segments that correspond to important steps of the demonstrated task. Existing video summarization datasets rely on manual frame-level annotations, making them subjective and limited in size. To overcome this, we first automatically generate pseudo summaries for a corpus of instructional videos by exploiting two key assumptions: (i) relevant steps are likely to appear in multiple videos of the same task (Task Relevance), and (ii) they are more likely to be described by the demonstrator verbally (Cross-Modal Saliency). We propose an instructional video summarization network that combines a context-aware temporal video encoder and a segment scoring transformer. Using pseudo summaries as weak supervision, our network constructs a visual summary for an instructional video given only video and transcribed speech. To evaluate our model, we collect a high-quality test set, WikiHow Summaries, by scraping WikiHow articles that contain video demonstrations and visual depictions of steps allowing us to obtain the ground-truth summaries. We outperform several baselines and a state-of-the-art video summarization model on this new benchmark. |
|
 |
Zhoutong Zhang, Forrester Cole, Zhengqi Li, Michael Rubinstein, Noah Snavely, William T. Freeman Structure and Motion for Casual Videos Proc. of the European Conference on Computer Vision (ECCV), 2022 Abstract | Paper Casual videos, such as those captured in daily life using a hand-held camera, pose problems for conventional structure-from-motion (SfM) techniques: the camera is often roughly stationary (not much parallax), and a large portion of the video may contain moving objects. Under such conditions, state-of-the-art SfM methods tend to produce erroneous results, often failing entirely. To address these issues, we propose CasualSAM, a method to estimate camera poses and dense depth maps from a monocular, casually-captured video. Like conventional SfM, our method performs a joint optimization over 3D structure and camera poses, but uses a pretrained depth prediction network to represent 3D structure rather than sparse keypoints. In contrast to previous approaches, our method does not assume motion is rigid or determined by semantic segmentation, instead optimizing for a per-pixel motion map based on reprojection error. Our method sets a new state-of-the-art for pose and depth estimation on the Sintel dataset, and produces high-quality results for the DAVIS dataset where most prior methods fail to produce usable camera poses. |
|
 |
Kfir Aberman, Junfeng He, Yossi Gandelsman, Inbar Mossari, David E. Jacobs, Kai Kohlhoff, Yael Pritch, Michael Rubinstein Deep Saliency Prior for Reducing Visual Distraction IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2022 Abstract | Paper | Webpage Using only a model that was trained to predict where people look at images, and no additional training data, we can produce a range of powerful editing effects for reducing distraction in images. Given an image and a mask specifying the region to edit, we backpropagate through a state-of-the-art saliency model to parameterize a differentiable editing operator, such that the saliency within the masked region is reduced. We demonstrate several operators, including: a recoloring operator, which learns to apply a color transform that camouflages and blends distractors into their surroundings; a warping operator, which warps less salient image regions to cover distractors, gradually collapsing objects into themselves and effectively removing them (an effect akin to inpainting); a GAN operator, which uses a semantic prior to fully replace image regions with plausible, less salient alternatives. The resulting effects are consistent with cognitive research on the human visual system (e.g., since color mismatch is salient, the recoloring operator learns to harmonize objects' colors with their surrounding to reduce their saliency), and, importantly, are all achieved solely through the guidance of the pretrained saliency model, with no additional supervision. We present results on a variety of natural images and conduct a perceptual study to evaluate and validate the changes in viewers' eye-gaze between the original images and our edited results |
|
 |
Sean Bae, Silviu Borac, Yunus Emre, Jonathan Wang, Jiang Wu, Mehr Kashyap, Si-Hyuck Kang, Liwen Chen, Melissa Moran, John Cannon, Eric S. Teasley, Allen Chai, Yun Liu, Neal Wadhwa, Mike Krainin, Michael Rubinstein, Alejandra Maciel, Michael V. McConnell, Shwetak Patel, Greg S. Corrado, James A. Taylor, Jiening Zhan, Ming Jack Po Prospective validation of smartphone-based heart rate and respiratory rate measurement algorithms Nature Communications Medicine, Apr 2022 Abstract | Paper | Blog | Available in Google Fit Measuring vital signs plays a key role in both patient care and wellness, but can be challenging outside of medical settings due to the lack of specialized equipment. In this study, we prospectively evaluated smartphone camera-based techniques for measuring heart rate (HR) and respiratory rate (RR) for consumer wellness use. HR was measured by placing the finger over the rear-facing camera, while RR was measured via a video of the participants sitting still in front of the front-facing camera. In the HR study of 95 participants (with a protocol that included both measurements at rest and post exercise), the mean absolute percent error (MAPE) ± standard deviation of the measurement was 1.6% ± 4.3%, which was significantly lower than the pre-specified goal of 5%. No significant differences in the MAPE were present across colorimeter-measured skin-tone subgroups: 1.8% ± 4.5% for very light to intermediate, 1.3% ± 3.3% for tan and brown, and 1.8% ± 4.9% for dark. In the RR study of 50 participants, the mean absolute error (MAE) was 0.78 ± 0.61 breaths/min, which was significantly lower than the pre-specified goal of 3 breath/min. The MAE was low in both healthy participants (0.70 ± 0.67 breaths/min), and participants with chronic respiratory conditions (0.80 ± 0.60 breaths/min). Our results validate that smartphone camera-based techniques can accurately measure HR and RR across a range of pre-defined subgroups. |
|
 |
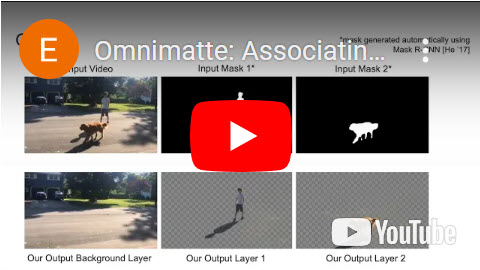
Erika Lu, Forrester Cole, Tali Dekel, Andrew Zisserman, William T. Freeman, Michael Rubinstein Omnimatte: Associating Objects and Their Effects in Video IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2021 (Oral presentation) Abstract | Paper | Webpage | BibTex Computer vision is increasingly effective at segmenting objects in images and videos; however, scene effects related to the objects—shadows, reflections, generated smoke, etc—are typically overlooked. Identifying such scene effects and associating them with the objects producing them is important for improving our fundamental understanding of visual scenes, and can also assist a variety of applications such as removing, duplicating, or enhancing objects in video. In this work, we take a step towards solving this novel problem of automatically associating objects with their effects in video. Given an ordinary video and a rough segmentation mask over time of one or more subjects of interest, we estimate an omnimatte for each subject—an alpha matte and color image that includes the subject along with all its related time-varying scene elements. Our model is trained only on the input video in a self-supervised manner, without any manual labels, and is generic—it produces omnimattes automatically for arbitrary objects and a variety of effects. We show results on real-world videos containing interactions between different types of subjects (cars, animals, people) and complex effects, ranging from semi-transparent elements such as smoke and reflections, to fully opaque effects such as objects attached to the subject. |
|
 |
Erika Lu, Forrester Cole, Tali Dekel, Weidi Xie, Andrew Zisserman, David Salesin, William T. Freeman, Michael Rubinstein Layered Neural Rendering for Retiming People in Video ACM Transactions on Graphics, Volume 39, Number 6 (Proc. SIGGRAPH ASIA), 2020 Abstract | Paper | Webpage | BibTex We present a method for retiming people in an ordinary, natural video — manipulating and editing the time in which different motions of individuals in the video occur. We can temporally align different motions, change the speed of certain actions (speeding up/slowing down, or entirely "freezing" people), or "erase" selected people from the video altogether. We achieve these effects computationally via a dedicated learning-based layered video representation, where each frame in the video is decomposed into separate RGBA layers, representing the appearance of different people in the video. A key property of our model is that it not only disentangles the direct motions of each person in the input video, but also correlates each person automatically with the scene changes they generate — e.g., shadows, reflections, and motion of loose clothing. The layers can be individually retimed and recombined into a new video, allowing us to achieve realistic, high-quality renderings of retiming effects for real-world videos depicting complex actions and involving multiple individuals, including dancing, trampoline jumping, or group running. |
|
 |
Sagie Benaim, Ariel Ephrat, Oran Lang, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Michal Irani, Tali Dekel SpeedNet: Learning the Speediness in Videos IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2020 (Oral presentation) Abstract | Paper | Webpage | BibTex We wish to automatically predict the "speediness" of moving objects in videos---whether they move faster, at, or slower than their "natural" speed. The core component in our approach is SpeedNet---a novel deep network trained to detect if a video is playing at normal rate, or if it is sped up. SpeedNet is trained on a large corpus of natural videos in a self-supervised manner, without requiring any manual annotations. We show how this single, binary classification network can be used to detect arbitrary rates of speediness of objects. We demonstrate prediction results by SpeedNet on a wide range of videos containing complex natural motions, and examine the visual cues it utilizes for making those predictions. Importantly, we show that through predicting the speed of videos, the model learns a powerful and meaningful space-time representation that goes beyond simple motion cues. We demonstrate how those learned features can boost the performance of self-supervised action recognition, and can be used for video retrieval. Furthermore, we also apply SpeedNet for generating time-varying, adaptive video speedups, which can allow viewers to watch videos faster, but with less of the jittery, unnatural motions typical to videos that are sped up uniformly. |
|
 |
Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik Speech2Face: Learning the Face Behind a Voice IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019 Abstract | Paper | Webpage | BibTex How much can we infer about a person's looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers. |
|
 |
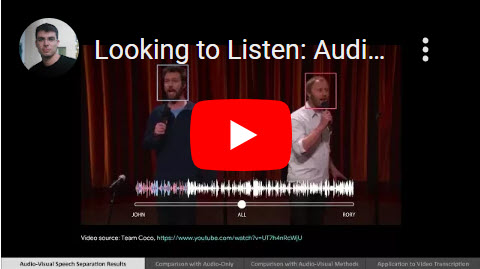
Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, Michael Rubinstein Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation ACM Transactions on Graphics, Volume 34, Number 4 (Proc. SIGGRAPH), 2018 Abstract | Paper | Webpage | BibTex Patented We present a joint audio-visual model for isolating a single speech signal from a mixture of sounds such as other speakers and background noise. Solving this task using only audio as input is extremely challenging and does not provide an association of the separated speech signals with speakers in the video. In this paper, we present a deep network-based model that incorporates both visual and auditory signals to solve this task. The visual features are used to "focus" the audio on desired speakers in a scene and to improve the speech separation quality. To train our joint audio-visual model, we introduce AVSpeech, a new dataset comprised of thousands of hours of video segments from the Web. We demonstrate the applicability of our method to classic speech separation tasks, as well as real-world scenarios involving heated interviews, noisy bars, and screaming children, only requiring the user to specify the face of the person in the video whose speech they want to isolate. Our method shows clear advantage over state-of-the-art audio-only speech separation in cases of mixed speech. In addition, our model, which is speaker-independent (trained once, applicable to any speaker), produces better results than recent audio-visual speech separation methods that are speaker-dependent (require training a separate model for each speaker of interest). |
|
 |
Tali Dekel, Michael Rubinstein, Ce Liu, William T. Freeman On the Effectiveness of Visible Watermarks IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017 Abstract | Paper | Webpage | BibTex Visible watermarking is a widely-used technique for marking and protecting copyrights of many millions of images on the web, yet it suffers from an inherent security flaw--watermarks are typically added in a consistent manner to many images. We show that this consistency allows to automatically estimate the watermark and recover the original images with high accuracy. Specifically, we present a generalized multi-image matting algorithm that takes a watermarked image collection as input and automatically estimates the "foreground" (watermark), its alpha matte, and the "background" (original) images. Since such an attack relies on the consistency of watermarks across image collection, we explore and evaluate how it is affected by various types of inconsistencies in the watermark embedding that could potentially be used to make watermarking more secured. We demonstrate the algorithm on stock imagery available on the web, and provide extensive quantitative analysis on synthetic watermarked data. A key takeaway message of this paper is that visible watermarks should be designed to not only be robust against removal from a single image, but to be more resistant to mass-scale removal from image collections as well. |
|
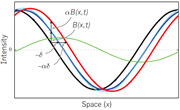 |
Neal Wadhwa, Hao-Yu Wu, Abe Davis, Michael Rubinstein, Eugene Shih, Gautham J. Mysore, Justin G. Chen, Oral Buyukozturk, John V. Guttag, William T. Freeman, Frédo Durand Eulerian Video Magnification and Analysis Communications of the ACM, January 2017 Abstract | PDF | CACM article online | BibTex The world is filled with important, but visually subtle signals. A person's pulse, the breathing of an infant, the sag and sway of a bridge—these all create visual patterns, which are too difficult to see with the naked eye. We present Eulerian Video Magnification, a computational technique for visualizing subtle color and motion variations in ordinary videos by making the variations larger. It is a microscope for small changes that are hard or impossible for us to see by ourselves. In addition, these small changes can be quantitatively analyzed and used to recover sounds from vibrations in distant objects, characterize material properties, and remotely measure a person's pulse.
|
|
 |
Tianfan Xue, Michael Rubinstein, Ce Liu, William T. Freeman A Computational Approach for Obstruction-Free Photography ACM Transactions on Graphics, Volume 34, Number 4 (Proc. SIGGRAPH), 2015 Abstract | Paper | Webpage | BibTex We present a unified computational approach for taking photos through reflecting or occluding elements such as windows and fences. Rather than capturing a single image, we instruct the user to take a short image sequence while slightly moving the camera. Differences that often exist in the relative position of the background and the obstructing elements from the camera allow us to separate them based on their motions, and to recover the desired background scene as if the visual obstructions were not there. We show results on controlled experiments and many real and practical scenarios, including shooting through reflections, fences, and raindrop-covered windows.
Patented |
|
 |
Abe Davis, Katherine L. Bouman, Justin G. Chen, Michael Rubinstein, Fredo Durand, William T. Freeman Visual Vibrometry: Estimating Material Properties from Small Motions in Video IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2015 (Oral presentation) Abstract | Paper | Webpage | BibTex The estimation of material properties is important for scene understanding, with many applications in vision, robotics, and structural engineering. This paper connects fundamentals of vibration mechanics with computer vision techniques in order to infer material properties from small, often imperceptible motion in video. Objects tend to vibrate in a set of preferred modes. The shapes and frequencies of these modes depend on the structure and material properties of an object. Focusing on the case where geometry is known or fixed, we show how information about an object's modes of vibration can be extracted from video and used to make inferences about that object's material properties. We demonstrate our approach by estimating material properties for a variety of rods and fabrics by passively observing their motion in high-speed and regular-framerate video. |
|
 |
Tali Dekel, Shaul Oron, Michael Rubinstein, Shai Avidan, William T. Freeman Best-Buddies Similarity for Robust Template Matching IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2015 Abstract | Paper | Webapge | BibTeX We propose a novel method for template matching in unconstrained environments. Its essence is the Best-Buddies
Similarity (BBS), a useful, robust, and parameter-free similarity measure between two sets of points. BBS is based on counting the number of Best-Buddies Pairs (BBPs)—pairs of points in source and target sets, where each point is the nearest neighbor of the other. BBS has several key features that make it robust against complex geometric deformations and high levels of outliers, such as those arising from background clutter and occlusions. We study these properties, provide a statistical analysis that justifies them, and demonstrate
the consistent success of BBS on a challenging realworld dataset. |
|
 |
Fredo Durand, William T. Freeman, Michael Rubinstein A World of Movement Scientific American, Volume 312, Number 1, January 2015 Article in SciAm | Videos | BibTeX |
|
 |
Tianfan Xue, Michael Rubinstein, Neal Wadhwa, Anat
Levin, Fredo Durand, William T. Freeman Refraction Wiggles for Measuring Fluid Depth and Velocity from Video Proc. of the European Conference on Computer Vision (ECCV), 2014 (Oral presentation) Abstract | Paper | Webpage | BibTeX Patented We present principled algorithms for measuring the velocity and
3D location of refractive fluids, such as hot air or gas, from natural
videos with textured backgrounds. Our main observation is that intensity
variations related to movements of refractive fluid elements, as
observed by one or more video cameras, are consistent over small
space-time volumes. We call these intensity variations “refraction
wiggles”, and use them as features for tracking and stereo fusion
to recover the fluid motion and depth from video sequences. We give
algorithms for 1) measuring the (2D, projected) motion of refractive
fluids in monocular videos, and 2) recovering the 3D position of
points on the fluid from stereo cameras. Unlike pixel intensities,
wiggles can be extremely subtle and cannot be known with the same
level of confidence for all pixels, depending on factors such as
background texture and physical properties of the fluid. We thus
carefully model uncertainty in our algorithms for robust estimation
of fluid motion and depth. We show results on controlled sequences,
synthetic simulations, and natural videos. Different from previous
approaches for measuring refractive flow, our methods operate directly
on videos captured with ordinary cameras, do not require auxiliary
sensors, light sources or designed backgrounds, and can correctly
detect the motion and location of refractive fluids even when they
are invisible to the naked eye. |
|
 |
Abe Davis, Michael Rubinstein, Neal Wadhwa, Gautham
Mysore, Fredo Durand, William T. Freeman The Visual Microphone: Passive Recovery of Sound from Video ACM Transactions on Graphics, Volume 33, Number 4 (Proc. SIGGRAPH), 2014 Abstract | Paper | Webpage | BibTeX Patented When sound hits an object, it causes small vibrations of the object’s
surface. We show how, using only high-speed video of the object,
we can extract those minute vibrations and partially recover the
sound that produced them, allowing us to turn everyday objects—a
glass of water, a potted plant, a box of tissues, or a bag of chips—into
visual microphones. We recover sounds from highspeed footage of
a variety of objects with different properties, and use both real
and simulated data to examine some of the factors that affect our
ability to visually recover sound. We evaluate the quality of recovered
sounds using intelligibility and SNR metrics and provide input and
recovered audio samples for direct comparison. We also explore how
to leverage the rolling shutter in regular consumer cameras to recover
audio from standard frame-rate videos, and use the spatial resolution
of our method to visualize how sound-related vibrations vary over
an object’s surface, which we can use to recover the vibration modes
of an object. |
|
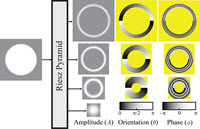 |
Neal Wadhwa, Michael Rubinstein, Fredo Durand, William
T. Freeman Riesz Pyramids for Fast Phase-Based Video Magnification IEEE International Conference on Computational Photography (ICCP), 2014 Abstract | Paper | Tech report | Webpage | BibTeX Patented CVPR 2014 Best Demo Award We present a new compact image pyramid representation, the Riesz
pyramid, that can be used for real-time, high quality, phase-based
video magnification. Our new representation is less overcomplete
than even the smallest two orientation, octave-bandwidth complex
steerable pyramid, and can be implemented using compact and efficient
linear filters in the spatial domain. Motion-magnified videos produced
using this new representation are of comparable quality to those
produced using the complex steerable pyramid. When used with phase-based
video magnification, the Riesz pyramid phase-shifts image features
along only their dominant orientation rather than every orientation
like the complex steerable pyramid. |
|
 |
Michael Rubinstein Analysis and Visualization of Temporal Variations in Video PhD Thesis, Massachusetts Institute of Technology, Feb 2014 Abstract | Thesis | Webpage | BibTeX George M. Sprowls Award for outstanding doctoral thesis in Computer Science at MIT Our world is constantly changing, and it is important for us to
understand how our environment changes and evolves over time. A
common method for capturing and communicating such changes is imagery
-- whether captured by consumer cameras, microscopes or satellites,
images and videos provide an invaluable source of information about
the time-varying nature of our world. Due to the great progress
in digital photography, such images and videos are now widespread
and easy to capture, yet computational models and tools for understanding
and analyzing time-varying processes and trends in visual data are
scarce and undeveloped. In this dissertation, we propose new computational techniques to efficiently represent, analyze and visualize both short-term and long-term temporal variation in videos and image sequences. Small-amplitude changes that are difficult or impossible to see with the naked eye, such as variation in human skin color due to blood circulation and small mechanical movements, can be extracted for further analysis, or exaggerated to become visible to an observer. Our techniques can also attenuate motions and changes to remove variation that distracts from the main temporal events of interest. The main contribution of this thesis is in advancing our knowledge on how to process spatiotemporal imagery and extract information that may not be immediately seen, so as to better understand our dynamic world through images and videos. |
|
 |
Neal Wadhwa, Michael Rubinstein, Fredo Durand, William
T. Freeman Phase-based Video Motion Processing ACM Transactions on Graphics, Volume 32, Number 4 (Proc. SIGGRAPH), 2013 Abstract | Paper | Webpage | BibTeX Patented We introduce a technique to manipulate small movements in videos
based on an analysis of motion in complex-valued image pyramids.
Phase variations of the coefficients of a complex-valued steerable
pyramid over time correspond to motion, and can be temporally processed
and amplified to reveal imperceptible motions, or attenuated to
remove distracting changes. This processing does not involve the
computation of optical flow, and in comparison to the previous Eulerian
Video Magnification method it supports larger amplification factors
and is significantly less sensitive to noise. These improved capabilities
broaden the set of applications for motion processing in videos.
We demonstrate the advantages of this approach on synthetic and
natural video sequences, and explore applications in scientific
analysis, visualization and video enhancement. |
|
 |
Michael Rubinstein, Armand Joulin, Johannes Kopf, Ce
Liu Unsupervised Joint Object Discovery and Segmentation in Internet Images IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2013 Abstract | Paper | Webpage | BibTeX We present a new unsupervised algorithm to discover and segment
out common objects from large and diverse image collections. In
contrast to previous co-segmentation methods, our algorithm performs
well even in the presence of significant amounts of noise images
(images not containing a common object), as typical for datasets
collected from Internet search. The key insight to our algorithm
is that common object patterns should be salient within each image,
while being sparse with respect to smooth transformations across
images. We propose to use dense correspondences between images to
capture the sparsity and visual variability of the common object
over the entire database, which enables us to ignore noise objects
that may be salient within their own images but do not commonly
occur in others. We performed extensive numerical evaluation on
established co-segmentation datasets, as well as several new datasets
generated using Internet search. Our approach is able to effectively
segment out the common object for diverse object categories, while
naturally identifying images where the common object is not present.
|
|
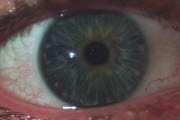 |
Michael Rubinstein, Neal Wadhwa, Fredo Durand, William
T. Freeman Revealing Invisible Changes In The World Science Vol. 339 No. 6119 Feb 1 2013 NSF International Science and Engineering Visualization Challenge (SciVis), 2012 Honorable Mention Article in Science | Video | NSF SciVis 2012 | BibTeX |
|
 |
Michael Rubinstein, Ce Liu, William T. Freeman Annotation Propagation in Large Image Databases via Dense Image Correspondence Proc. of the European Conference on Computer Vision (ECCV), 2012 Abstract | Paper | Webpage | BibTeX Patented Our goal is to automatically annotate many images with a set of
word tags and a pixel-wise map showing where each word tag occurs.
Most previous approaches rely on a corpus of training images where
each pixel is labeled. However, for large image databases, pixel
labels are expensive to obtain and are often unavailable. Furthermore,
when classifying multiple images, each image is typically solved
for independently, which often results in inconsistent annotations
across similar images. In this work, we incorporate dense image
correspondence into the annotation model, allowing us to make do
with significantly less labeled data and to resolve ambiguities
by propagating inferred annotations from images with strong local
visual evidence to images with weaker local evidence. We establish
a large graphical model spanning all labeled and unlabeled images,
then solve it to infer annotations, enforcing consistent annotations
over similar visual patterns. Our model is optimized by efficient
belief propagation algorithms embedded in an expectation-maximization
(EM) scheme. Extensive experiments are conducted to evaluate the
performance on several standard large-scale image datasets, showing
that the proposed framework outperforms state-of-the-art methods. |
|
| Michael Rubinstein, Ce Liu, William T. Freeman Towards Longer Long-Range Motion Trajectories Proc. of the British Machine Vision Conference (BMVC), 2012 Abstract | Paper | Supplemental (.zip) | BMVC'12 poster | BibTeX Although dense, long-rage, motion trajectories are a prominent representation
of motion in videos, there is still no good solution for constructing
dense motion tracks in a truly long-rage fashion. Ideally, we would
want every scene feature that appears in multiple, not necessarily
contiguous, parts of the sequence to be associated with the same
motion track. Despite this reasonable and clearly stated objective,
there has been surprisingly little work on general-purpose algorithms
that can accomplish that task. State-of-the-art dense motion trackers
process the sequence incrementally in a frame-by-frame manner, and
associate, by design, features that disappear and reappear in the
video, with different tracks, thereby losing important information
of the long-term motion signal. In this paper, we strive towards
an algorithm for producing generic long-range motion trajectories
that are robust to occlusion, deformation and camera motion. We
leverage accurate local (short-range) trajectories produced by current
motion tracking methods and use them as an initial estimate for
a global (long-range) solution. Our algorithm re-correlates the
short trajectory estimates and links them to form a long-range motion
representation by formulating a combinatorial assignment problem
that is defined and optimized globally over the entire sequence.
This allows to correlate tracks in arbitrarily distinct parts of
the sequence, as well as handle track ambiguities by spatiotemporal
regularization. We report results of the algorithm on synthetic
examples, natural and challenging videos, and evaluate the representation
for action recognition. |
||
 |
Hao-Yu Wu, Michael Rubinstein, Eugene Shih, John Guttag,
Fredo Durand, William T. Freeman Eulerian Video Magnification for Revealing Subtle Changes in the World ACM Transactions on Graphics, Volume 31, Number 4 (Proc. SIGGRAPH), 2012 Abstract | Paper | Webpage | BibTeX Patented SIGGRAPH 2023 Test-of-Time Award Our goal is to reveal temporal variations in videos that are difficult
or impossible to see with the naked eye and display them in an indicative
manner. Our method, which we call Eulerian Video Magnification,
takes a standard video sequence as input, and applies spatial decomposition,
followed by temporal filtering to the frames. The resulting signal
is then amplified to reveal hidden information. Using our method,
we are able to visualize the flow of blood as it fills the face
and to amplify and reveal small motions. Our technique can be run
in real time to instantly show phenomena occurring at the temporal
frequencies selected by the user. |
|
 |
Michael Rubinstein, Ce Liu, Peter Sand, Fredo Durand,
William T. Freeman Motion Denoising with Application to Time-lapse Photography IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2011 Abstract | Paper | Webpage | BibTeX Motions can occur over both short and long time scales. We introduce
motion denoising, which treats short-term changes as noise, long-term
changes as signal, and rerenders a video to reveal the underlying
long-term events. We demonstrate motion denoising for time-lapse
videos. One of the characteristics of traditional time-lapse imagery
is stylized jerkiness, where short-term changes in the scene appear
as small and annoying jitters in the video, often obfuscating the
underlying temporal events of interest. We apply motion denoising
for resynthesizing time-lapse videos showing the long-term evolution
of a scene with jerky short-term changes removed. We show that existing
filtering approaches are often incapable of achieving this task,
and present a novel computational approach to denoise motion without
explicit motion analysis. We demonstrate promising experimental
results on a set of challenging time-lapse sequences. |
|
 |
Michael Rubinstein, Diego Gutierrez, Olga Sorkine,
Ariel Shamir A Comparative Study of Image Retargeting ACM Transactions on Graphics, Volume 29, Number 5 (Proc. SIGGRAPH Asia), 2010 Abstract | Paper | Webpage | BibTeX The numerous works on media retargeting call for a methodological
approach for evaluating retargeting results. We present the first
comprehensive perceptual study and analysis of image retargeting.
First, we create a benchmark of images and conduct a large scale
user study to compare a representative number of state-of-the-art
retargeting methods. Second, we present analysis of the users’ responses,
where we find that humans in general agree on the evaluation of
the results and show that some retargeting methods are consistently
more favorable than others. Third, we examine whether computational
image distance metrics can predict human retargeting perception.
We show that current measures used in this context are not necessarily
consistent with human rankings, and demonstrate that better results
can be achieved using image features that were not previously considered
for this task. We also reveal specific qualities in retargeted media
that are more important for viewers. The importance of our work
lies in promoting better measures to assess and guide retargeting
algorithms in the future. The full benchmark we collected, including
all images, retargeted results, and the collected user data, are
available to the research community for further investigation. |
|
 |
Michael Rubinstein Discrete Approaches to Content-aware Image and Video Retargeting MSc Thesis, The Interdisciplinary Center, May 2009 pdf | High-resolution pdf (70MB) | BibTeX |
|
 |
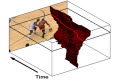
Michael Rubinstein, Ariel Shamir, Shai Avidan Multi-operator Media Retargeting ACM Transactions on Graphics, Volume 28, Number 3 (Proc. SIGGRAPH), 2009 Abstract | Paper | Webpage | BibTeX Patented Content aware resizing gained popularity lately and users can now
choose from a battery of methods to retarget their media. However,
no single retargeting operator performs well on all images and all
target sizes. In a user study we conducted, we found that users
prefer to combine seam carving with cropping and scaling to produce
results they are satisfied with. This inspires us to propose an
algorithm that combines different operators in an optimal manner.
We define a resizing space as a conceptual multi-dimensional space
combining several resizing operators, and show how a path in this
space defines a sequence of operations to retarget media. We define
a new image similarity measure, which we term Bi-Directional Warping
(BDW), and use it with a dynamic programming algorithm to find an
optimal path in the resizing space. In addition, we show a simple
and intuitive user interface allowing users to explore the resizing
space of various image sizes interactively. Using key-frames and
interpolation we also extend our technique to retarget video, providing
the flexibility to use the best combination of operators at different
times in the sequence. |
|
 |
Michael Rubinstein, Ariel Shamir, Shai Avidan Improved Seam Carving for Video Retargeting ACM Transactions on Graphics, Volume 27, Number 3 (Proc. SIGGRAPH), 2008 Abstract | Paper | Webpage | Code | BibTex Patented Implemented in Adobe Photoshop as Content-aware scaling Video, like images, should support content aware resizing. We present
video retargeting using an improved seam carving operator. Instead
of removing 1D seams from 2D images we remove 2D seam manifolds
from 3D space-time volumes. To achieve this we replace the dynamic
programming method of seam carving with graph cuts that are suitable
for 3D volumes. In the new formulation, a seam is given by a minimal
cut in the graph and we show how to construct a graph such that
the resulting cut is a valid seam. That is, the cut is monotonic
and connected. In addition, we present a novel energy criterion
that improves the visual quality of the retargeted images and videos.
The original seam carving operator is focused on removing seams
with the least amount of energy, ignoring energy that is introduced
into the images and video by applying the operator. To counter this,
the new criterion is looking forward in time - removing seams that
introduce the least amount of energy into the retargeted result.
We show how to encode the improved criterion into graph cuts (for
images and video) as well as dynamic programming (for images). We
apply our technique to images and videos and present results of
various applica |
|
 |
Ariel Shamir, Michael Rubinstein, Tomer Levinboim Inverse Computer Graphics: Parametric Comics Creation from 3D Interaction IEEE Computer Graphics & Applications, Volume 26, Number 3, 30-38, 2006 Abstract | Paper | Webpage | BibTeX There are times when Computer Graphics is required to be succinct
and simple. Carefully chosen simplified and static images can portray
a narration of a story as effectively as 3D photo-realistic continuous
graphics. In this paper we present an automatic system which transforms
continuous graphics originating from real 3D virtualworld interactions
into a sequence of comics images. The system traces events during
the interaction and then analyzes and breaks them into scenes. Based
on user defined parameters of point-ofview and story granularity
it chooses specific time-frames to create static images, renders
them, and applies post-processing to reduce their cluttering. The
system utilizes the same principal of intelligent reduction of details
in both temporal and spatial domains for choosing important events
and depicting them visually. The end result is a sequence of comics
images which summarize the main happenings and present them in a
coherent, concise and visually pleasing manner. |
Code and Data
 |
Object Discovery and Segmentation Internet Datasets The Internet image collections we used for the evaluation in our CVPR'13 paper, with human foreground-background masks, and the segmentation results by our method and by other co-segmentation techniques. |
|
 |
Eulerian Video
Magnification MATLAB/C++ implementation of our method, with code that reproduces all the results in our SIGGRAPH'12 paper. This technology is patented by MIT, and the code is provided for non-commercial research purposes only. |
|
 |
 A dataset of 80 images and retargeted results, ranked by human viewers. The project website contains all the data we collected and also provides a nice synopsis of the current state of image retargeting research. |
|
 |
Image Retargeting Survey The system I've developed for collecting user feedback on image retargeting results. It is based on the linked-paired comparison design to collect and analyze data when the number of stimuli is very large. The code is written in HTML, PHP and JavaScript. It supports multiple experiment designs, and can be easily used with Amazon Mechanical Turk. See my paper and the project website for further details. A live demo is available here. |
|
 |
Seam Carving (v1.0, 2009-04-10) A MATLAB re-implementation of the seam carving method I worked on at MERL. It is provided for research/educational purposes only. This algorithm is patented and owned by Mitsubishi Electric Research Labs, Cambridge MA. The code supports backward and forward energy using both the dynamic programming and graph cut formulations. See demo.m for usage example. |
|
||
|
 |
 |
|
|
|
For more conference talks, see the project web pages under Publications above.
Some other non-conference talks I gave here and there: |
|
Press Coverage (to be updated...)
 |
 |
 |
 |
 |
 |
(scroll to 3:30) |
 |
 |
 |
 |
 |
 |
More press...
Links
- The
fourfive most important things in my life - Personal wiki
- MIT Computer Vision Group
- Microsoft Research
- Google Research
Miscellaneous
|


|


