|
I am an Associate Professor in the department of Electrical
Engineering and Computer Science (EECS) at MIT
and co-founder of Eka Robotics. I obtained my Ph.D. from UC Berkeley and undergraduate degree from IIT Kanpur. Previously, I co-founded SafelyYou Inc. that builds fall prevention technology. Advisor to Tutor Intelligence, and Lab0 Inc.
Follow @pulkitology / LinkedIn / Email / CV / Biography / Google Scholar |

|
|
The overarching research interest is to build machines that have similar manipulation and locomotion abilities as humans. These machines will automatically and continuously learn about their environment and exhibit both common sense and physical intuition. I refer to this line of work as "computational sensorimotor learning". It encompasses problems in perception, control, hardware design, robotics, reinforcement learning, and other learning approaches to control. My past work has also drawn inspiration from cognitive science, and neuroscience. Ph.D. Thesis (Computational Sensorimotor Learning) / Thesis Talk / Bibtex TEDxMIT Talk: Why machines can play chess but can't open doors? (i.e., why is robotics hard?) |
|
Courses
Professional Education |
|
RL Razor gets the Outstanding Paper Award, NeurIPS workshop on Continual and Compatible Foundation Models, 2025.
|
|
The lab is an unsual collection of folks working on something that is unconceivable/unthinkable, but not impossible in our lifetime: General Artificial Intelligence. Life is short, do what you must do :-) I like to call my group: Improbable AI Lab.
Post Docs
Graduate Students
Research Staff
Masters of Engineering (MEng. Students) and Undergraduate Researchers (UROPs)
Openings |
|
Pathway to Robotic Intelligence , MIT Schwarzman College of Computing Talk, 2024. |
|
|
|
|
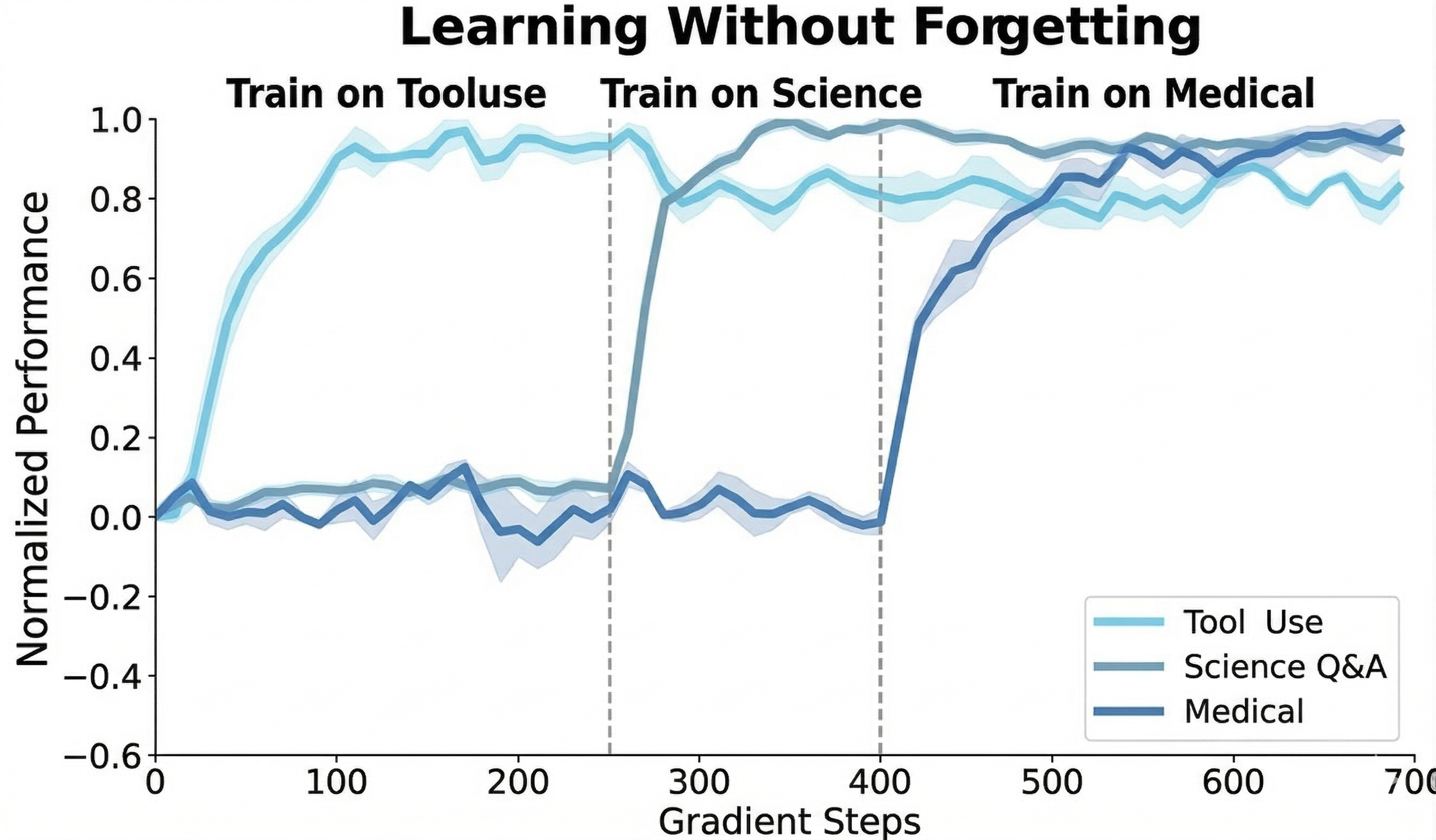
Idan Shenfeld, Mehul Damani, Jonas Hübotter, Pulkit Agrawal arXiv, 2026 paper / project page / bibtex SDFT enables on-policy learning directly from demonstrations, preserving prior capabilities while acquiring new skills. |

|
Gabriel B. Margolis*, Michelle Wang*, Nolan Fey, Pulkit Agrawal arXiv, 2025 paper / project page / bibtex Learning humanoid policies that compliantly respond to external forces with user-controllable stiffness. |

|
Hao-Shu Fang, Branden Romero, Yichen Xie, Arthur Hu, Bo-Ruei Huang, Juan Alvarez, Matthew Kim, Gabe Margolis, Kavya Anbarasu, Masayoshi Tomizuka, Edward Adelson, Pulkit Agrawal arXiv, 2025 (Best Paper Award, Dexterous Manipulation Workshop, RSS, 2025) paper / project page / bibtex DEXOP is a passive, force-transparent hand exoskeleton for faster and higher-quality data collection. |

|
Martin Peticco, Gabriella Ulloa, John Marangola, Nitish Dashora, Pulkit Agrawal Workshop on Robot Hardware-Aware Intelligence, RSS, 2025 paper / project page / bibtex DexWrist is a robotic wrist that leverages a novel decoupled parallel kinematic mechanism and quasi-direct-drive actuation to perform constrained and contact-rich tasks. |

|
Bipasha Sen, Michelle Wang, Nandini Thakur, Aditya Agarwal, Pulkit Agrawal arXiv, 2024 paper / bibtex |
|
Jyothish Pari, Samy Jelassi, Pulkit Agrawal arXiv, 2024 paper / project page / code / bibtex |
|
Sathwik Karnik, Zhang-Wei Hong, Nishant Abhangi, Yen-Chen Lin, Tsun-Hsuan Wang, Pulkit Agrawal arXiv, 2024 paper / project page / code / bibtex |
|
|
|
|
RL's Razor: Why Online Reinforcement Learning Forgets Less
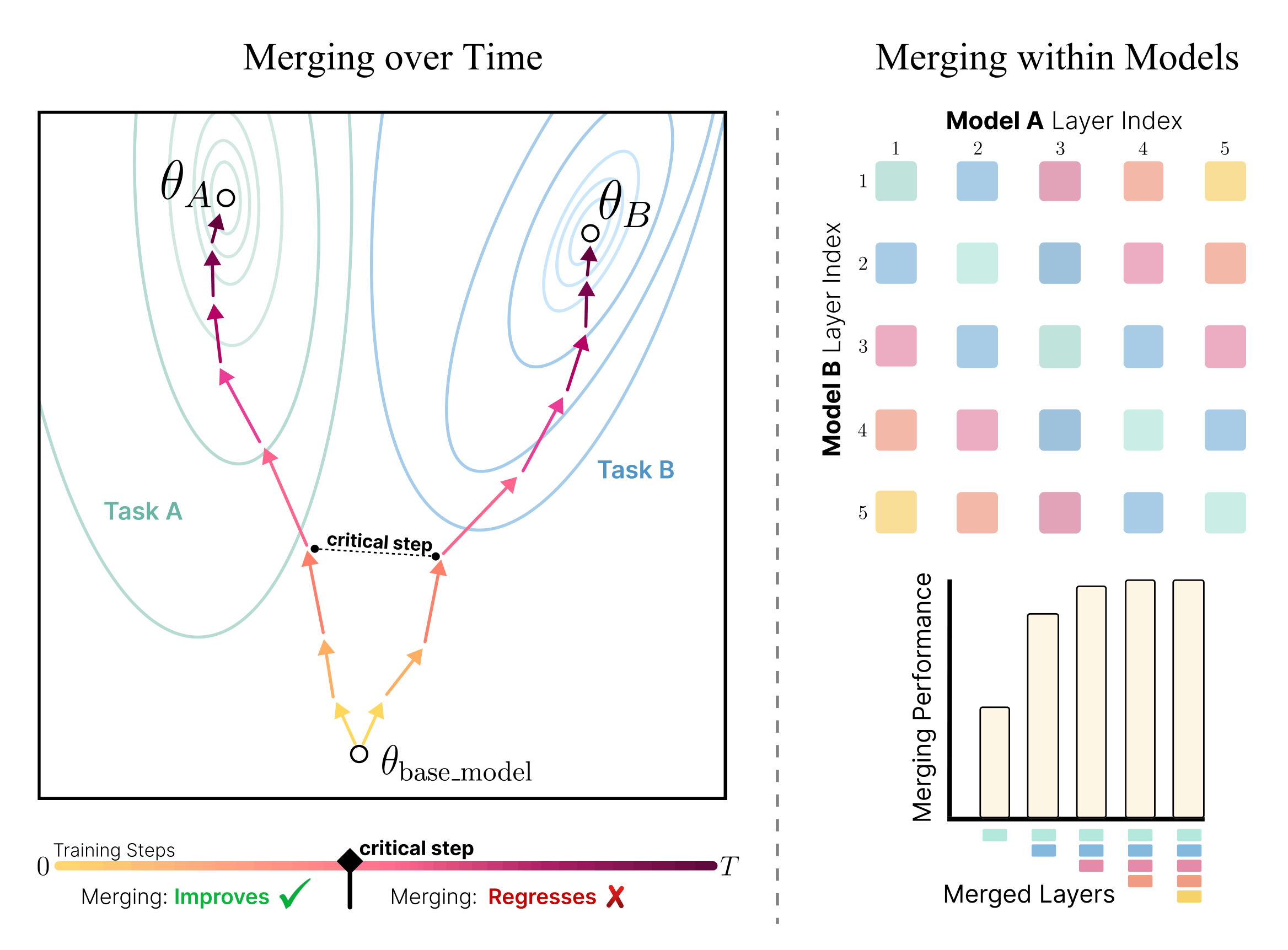
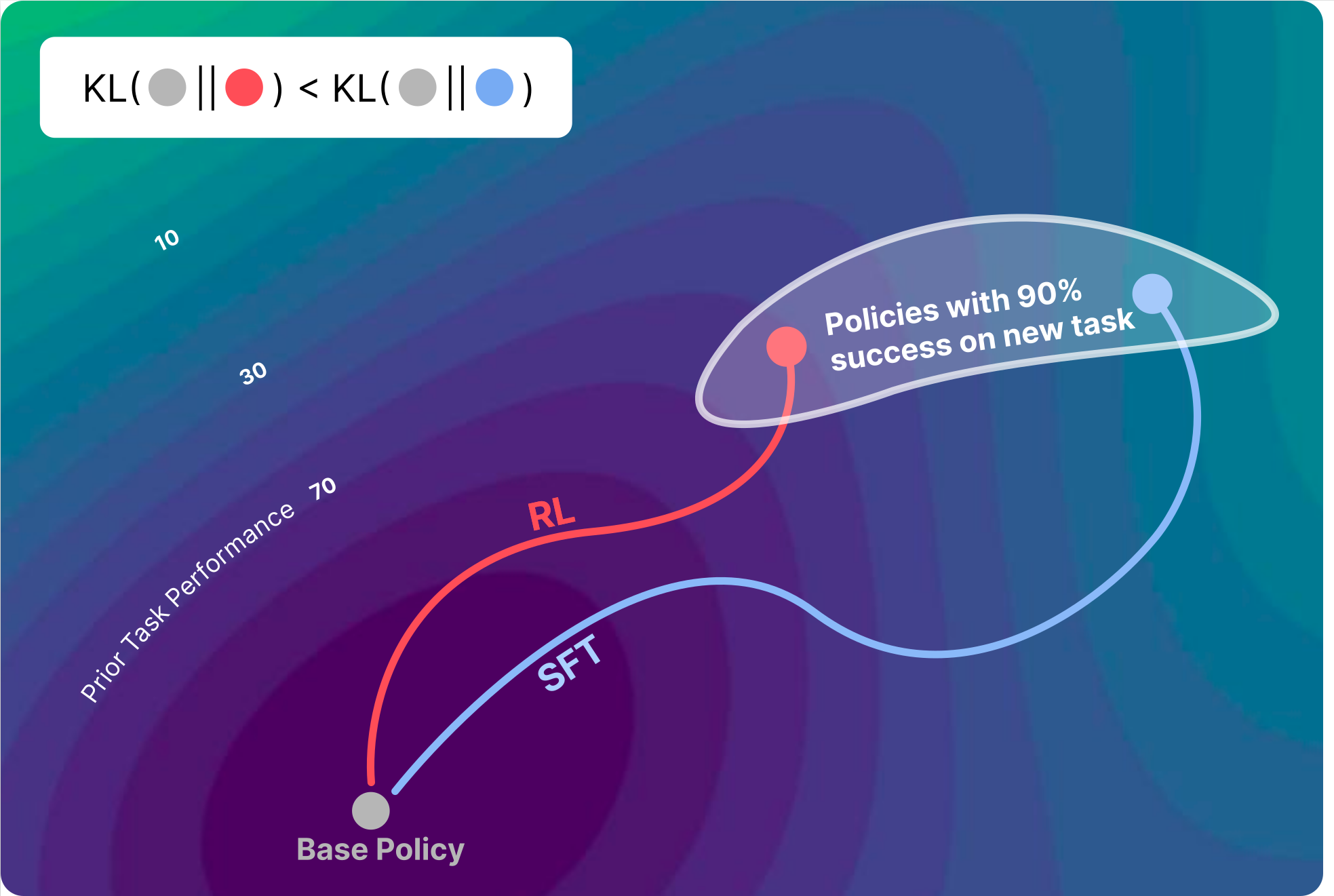
Idan Shenfeld, Jyothish Pari, Pulkit Agrawal ICLR, 2025 (Best Paper Award, CCFM Workshop, Neurips, 2025) paper / project page / bibtex On-policy RL implicitly biases toward KL-minimal solutions when fine-tuning, preserving prior knowledge significantly better than supervised fine-tuning. |
|
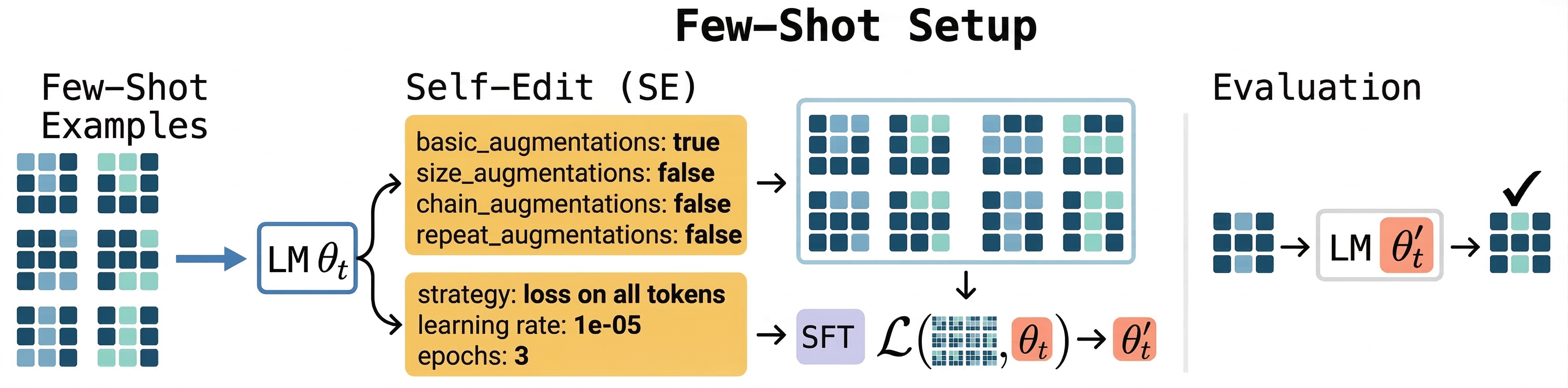
Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, Pulkit Agrawal NeurIPS, 2025 paper / project page / bibtex A framework that enables language models to self-adapt by generating their own finetuning data and optimization instructions. |
|
Zhen Zhang, Zhichu Ren, Chia-Wei Hsu, Weibin Chen, Zhang-Wei Hong, Pulkit Agrawal, Yang Shao-Horn, Ju Li Nature, 2025 paper / bibtex |
|
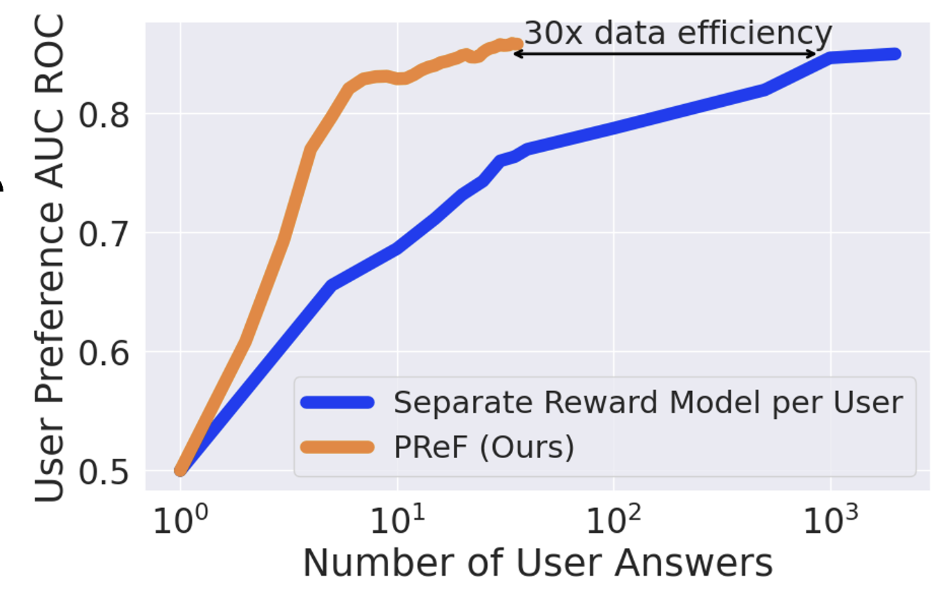
Idan Shenfeld*, Felix Faltings*, Pulkit Agrawal, Aldo Pacchiano CoLM, 2025 paper / bibtex Framework for personalizing large models assuming that human preferences lie on a low-dimensional manifold. |

|
Nolan Fey, Gabriel B. Margolis, Martin Peticco, Pulkit Agrawal RSS, 2025 paper / project page / bibtex Enhancing the sim-to-real transfer for extreme whole-body manipulation. |

|
Marcel Torne, Arhan Jain, Jiayi Yuan, Vidaaranya Macha, Lars Ankile, Anthony Simeonov, Pulkit Agrawal, Abhishek Gupta RSS, 2025 paper / project page / bibtex A pipeline for scaling up data collection and learning in simulation where the performance scales superlinearly with human effort. |
|
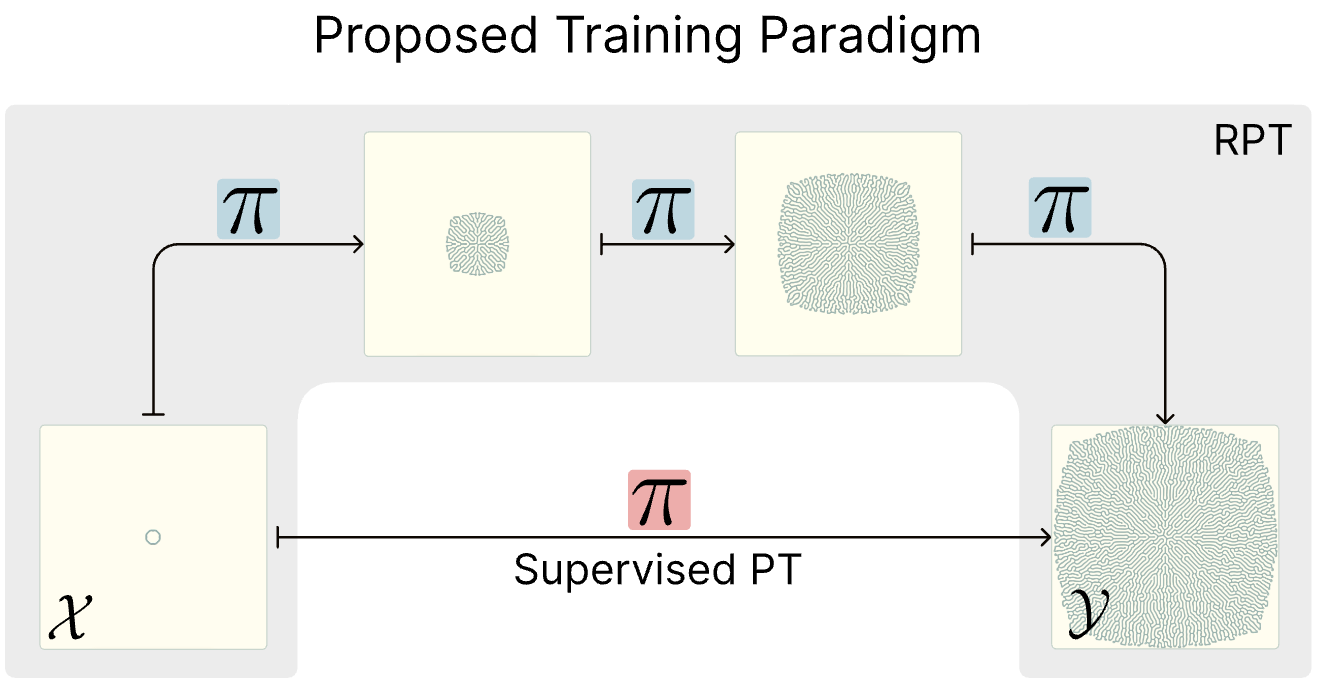
Seungwook Han, Jyothish Pari, Samuel J. Gershman, Pulkit Agrawal ICML, 2025 (Spotlight) paper / project page / bibtex |
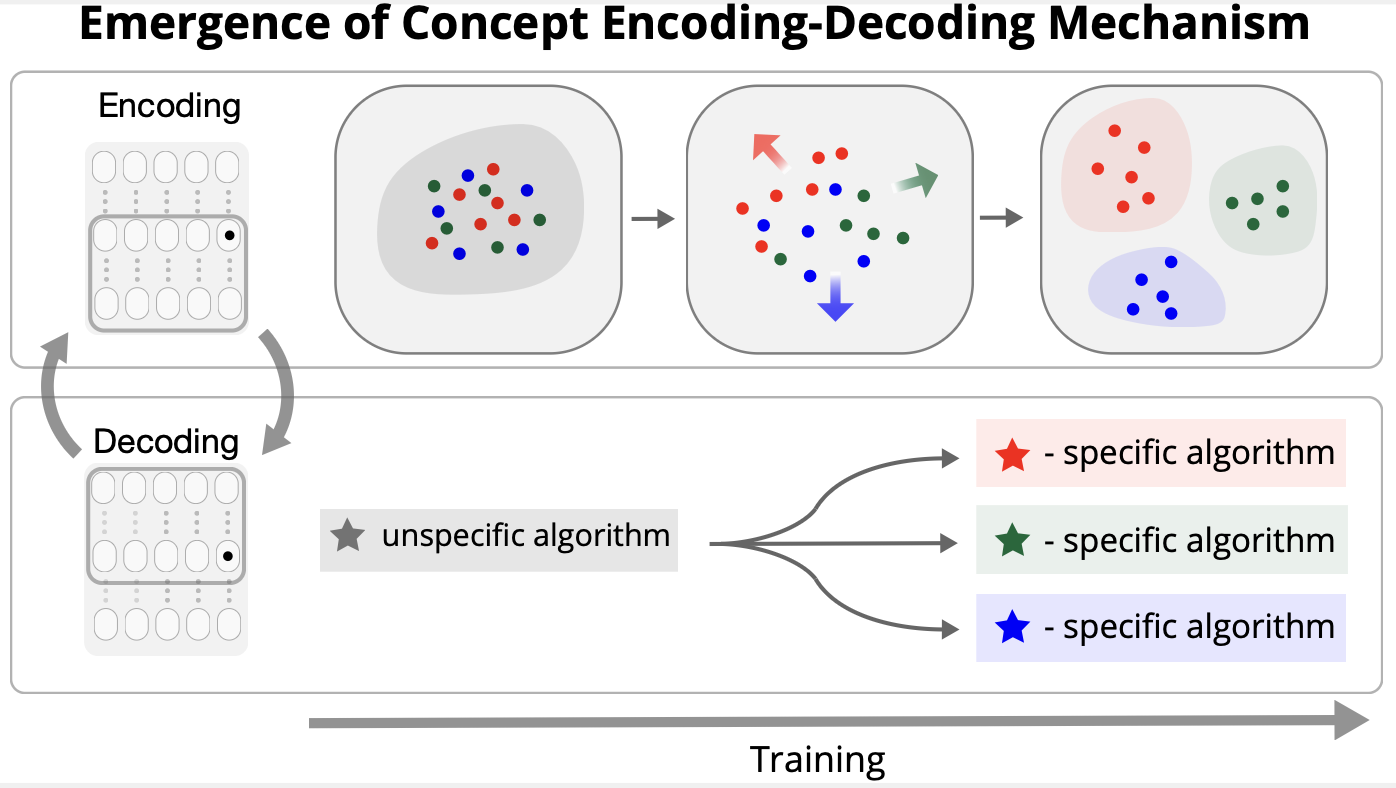
|
Seungwook Han, Jinyeop Song, Jeff Gore, Pulkit Agrawal ICML, 2025 (Spotlight) paper / bibtex |

|
Younghyo Park, Jagdeep Bhatia, Lars Ankile, Pulkit Agrawal ICRA, 2025 paper / bibtex A teleoperation platform that leverages cloud-based simulation and augmented reality (AR) to revolutionize robotic data collection. |
|
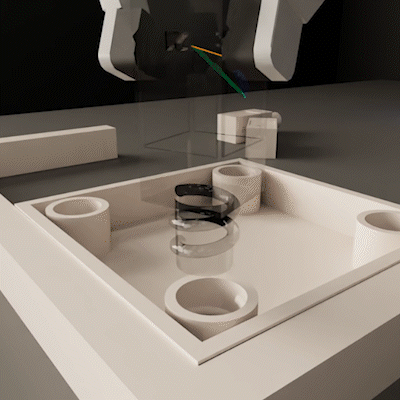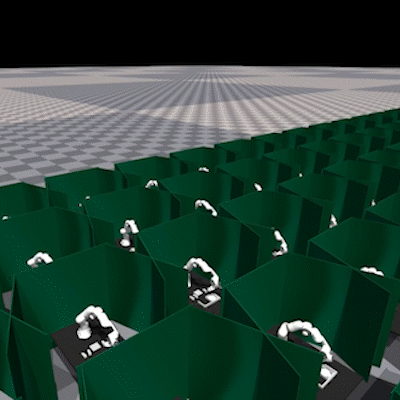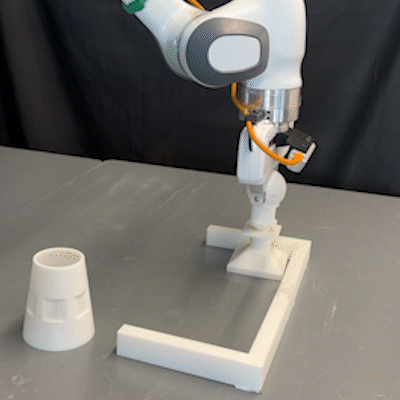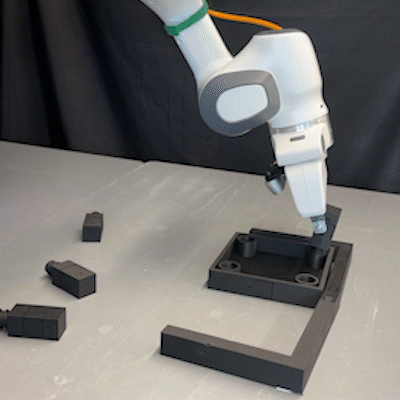
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, Pulkit Agrawal ICRA, 2025 paper / project page / code / bibtex Refining behavior-cloned diffusion model policies using RL. |
|
Tao Chen, Eric Cousineau, Naveen Kuppuswamy, Pulkit Agrawal ICRA, 2025 paper / project page / bibtex A robotic system that peels vegetables with a dexterous robot hand. |
|
|
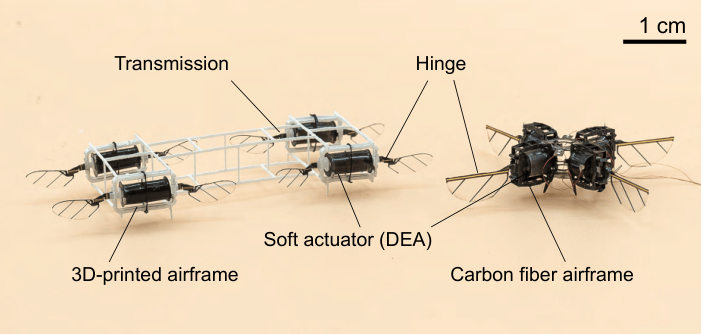
Yi-Hsuan Hsiao, Wei-Tung Chen, Yun-Sheng Chang, Pulkit Agrawal, YuFeng Chen RoboSoft, 2025 (Spotlight) paper / bibtex |
|
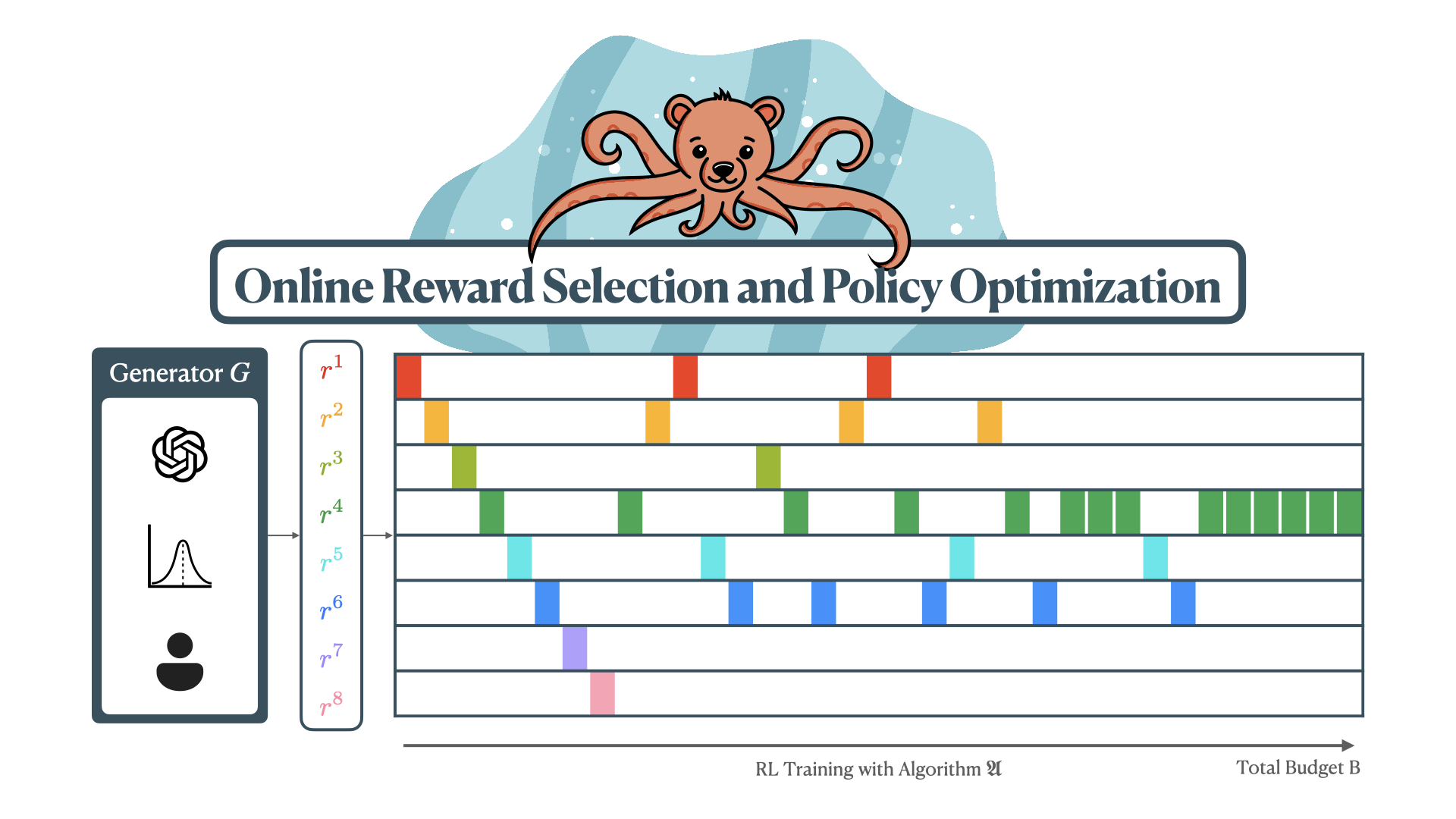
Chen Bo Calvin Zhang, Zhang-Wei Hong, Aldo Pacchiano, Pulkit Agrawal ICLR, 2025 paper / bibtex Casting reward selection as a model selection leads to faster learning (upto 8x) and better performance (upto 2x) when training RL agents with provable regret guarantees. |
|
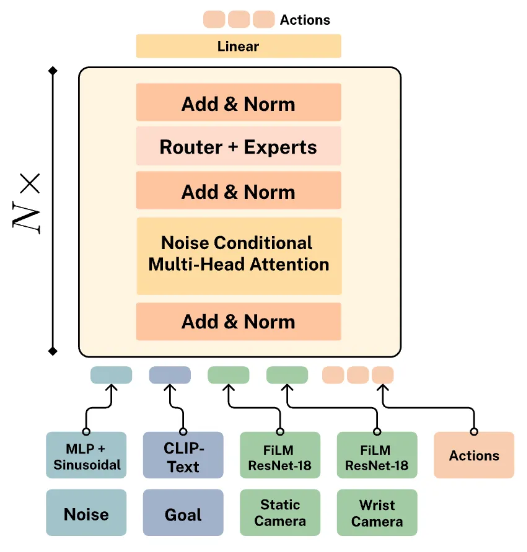
Moritz Reuss*, Jyo Pari*, Pulkit Agrawal, Rudolf Lioutikov (*equal contribution) ICLR , 2025 paper / bibtex MoDE is a novel architecture that uses sparse experts and noise-conditioned routing. |
|
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, Max Simchowitz ICLR, 2025 paper / code / bibtex DPPO is an algorithmic framework for fine-tuning diffusion-based policies using reinforcement learning. |
|
|
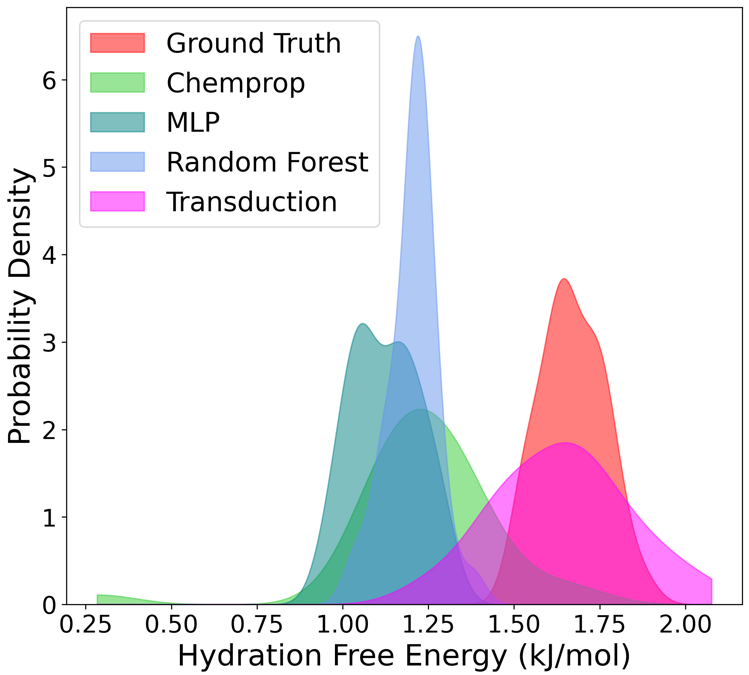
Nofit Segal*, Aviv Netanyahu*, Kevin Greenman, Pulkit Agrawal†, Rafael Gómez-Bombarelli† (*equal contribution; †equal advising) npj Computational Materials, 2025 paper / code / bibtex Extrapolating property prediction in materials science. |
|
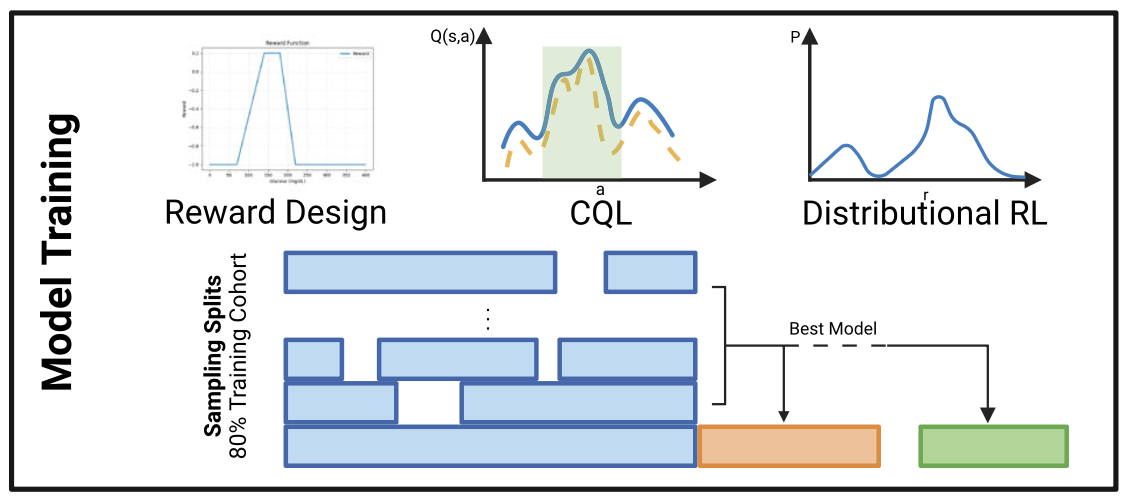
Jacob M. Desman, Zhang-Wei Hong, Moein Sabounchi et al., Pulkit Agrawal npj Digital Medicine, 2025 paper / bibtex An offline RL algorithm for optimizing insulin dosing after cardiac surgery. |
|
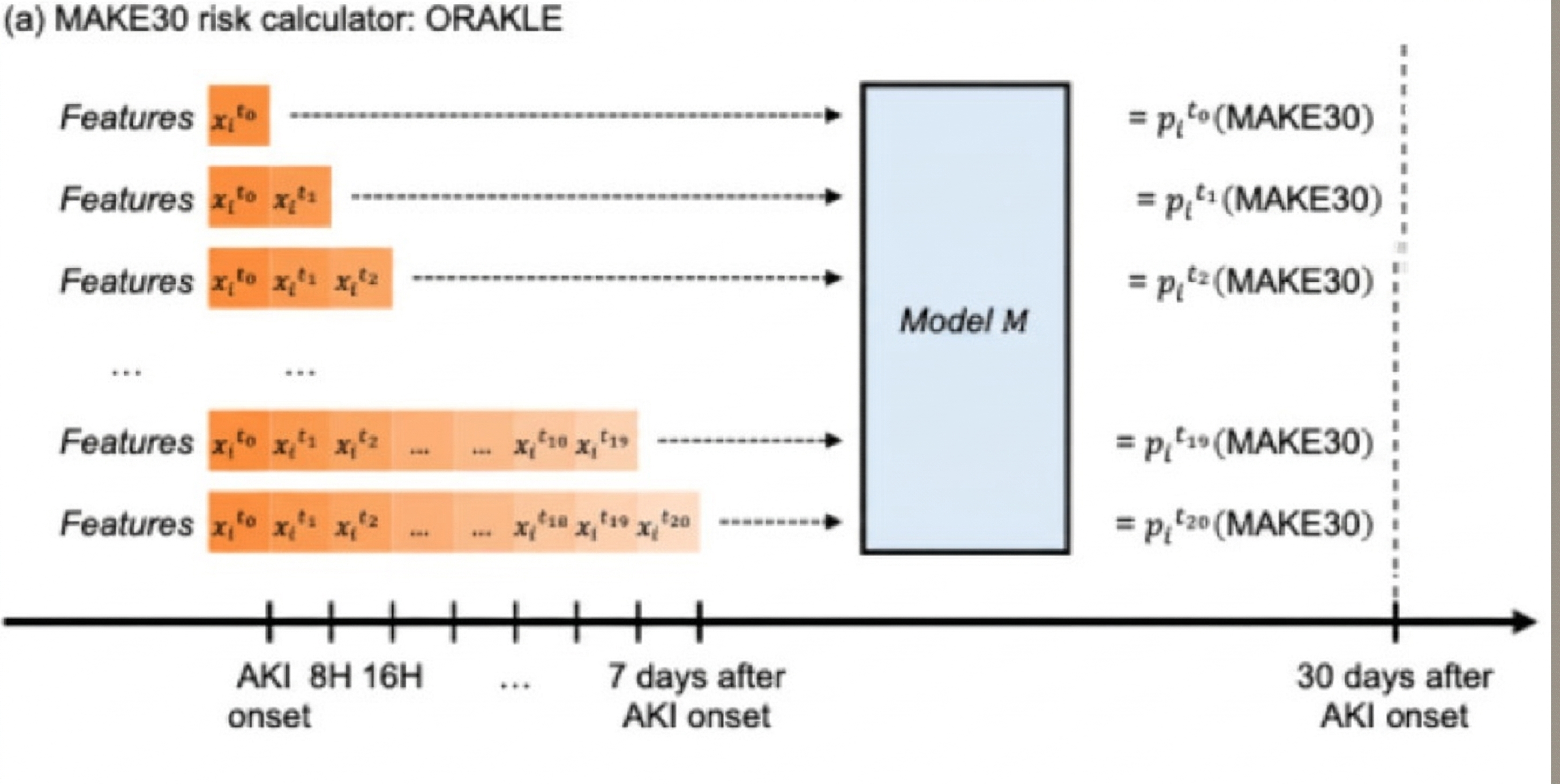
Wonsuk Oh, Marinela Veshtaj, Ashwin Sawant, Pulkit Agrawal et al. Critical Care, 2025 paper / bibtex |
|
Moein Sabounchi, Jacob M. Desman, Idan Shenfeld et al., Pulkit Agrawal Journal of the American Society of Nephrology, 2025 |
|

|
Branden Romero*, Hao-Shu Fang*, Pulkit Agrawal, Edward Adelson IROS, 2024 paper / project page / bibtex A dexterous hand with proprioceptive actuation fully covered with tactile sensing. |
|
Marcel Torne Villasevil , Anthony Simeonov, Zechu Li, April Chan, Tao Chen, Abhishek Gupta, Pulkit Agrawal RSS, 2024 paper / project page / bibtex A framework to train robots on scans of real-world scenes. |
|

|
Aviv Netanyahu, Yilun Du, Antonia Bronars, Jyothish Pari, Joshua Tenenbaum, Tianmin Shu, Pulkit Agrawal NeurIPS, 2024 paper / project page / code / bibtex Few-shot continual learning via generative modeling. |
|
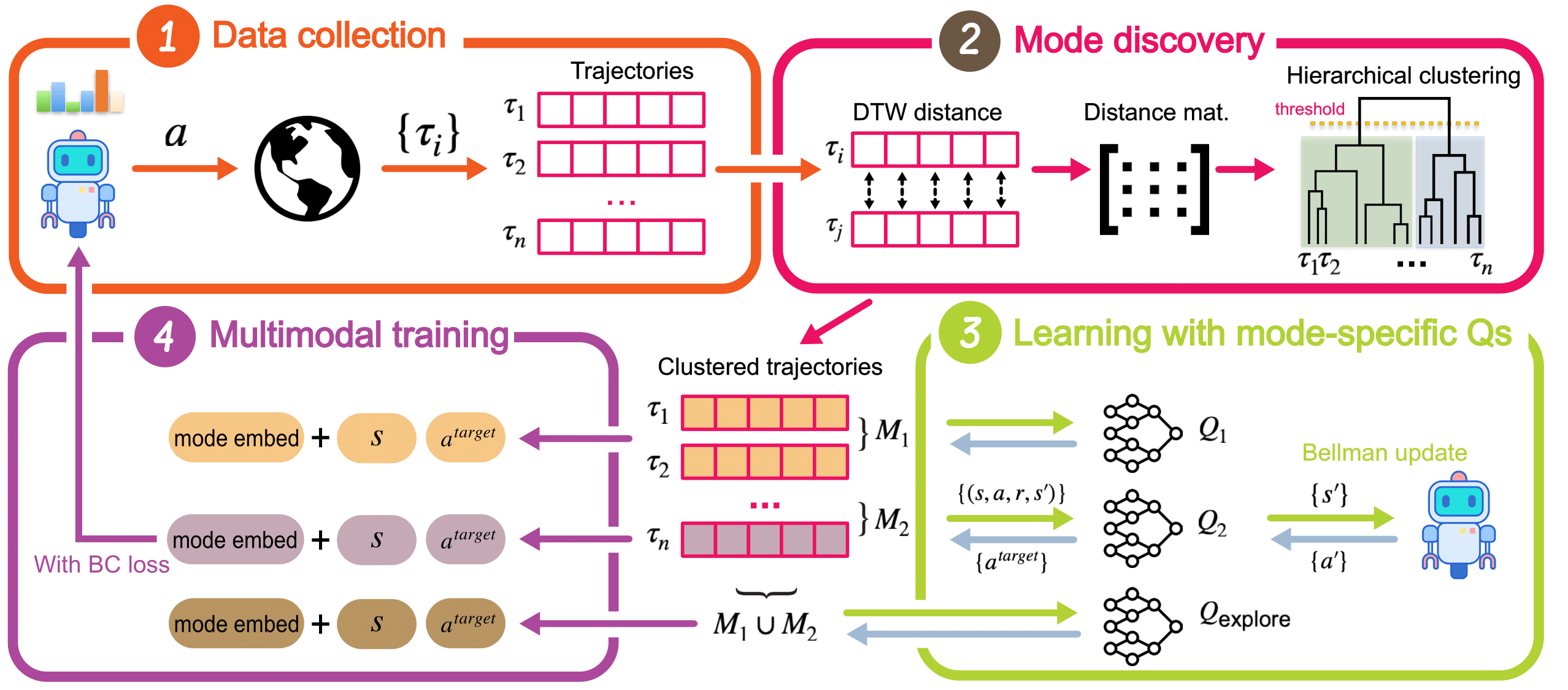
Steven Li, Rickmer Krohn, Tao Chen, Anurag Ajay, Pulkit Agrawal, Georgia Chalvatzaki NeurIPS, 2024 paper / bibtex Learning distributionally multi-modal behaviors from scratch with diffusion policies and RL. |
|
Chi-Chang Lee, Zhang-Wei Hong, Pulkit Agrawal NeurIPS, 2024 paper / code / bibtex |
|
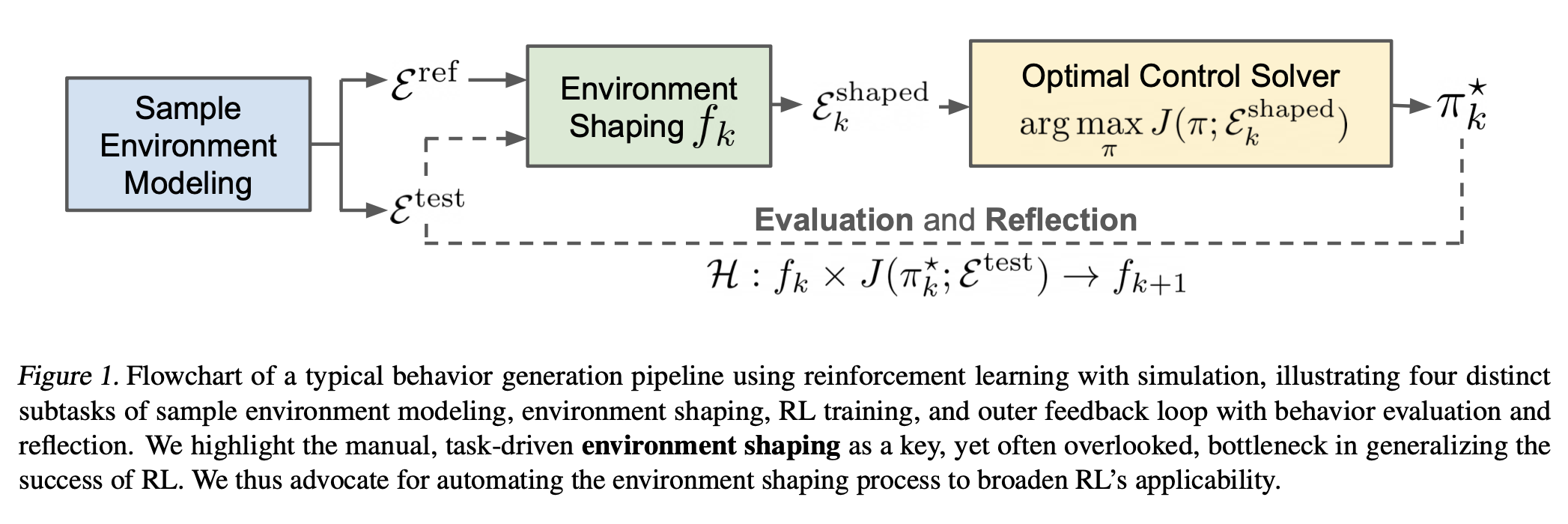
Younghyo Park*, Gabriel Margolis*, Pulkit Agrawal ICML, 2024 (Oral) paper / project page / bibtex Automatic environment shaping is the next frontier in RL. |
|
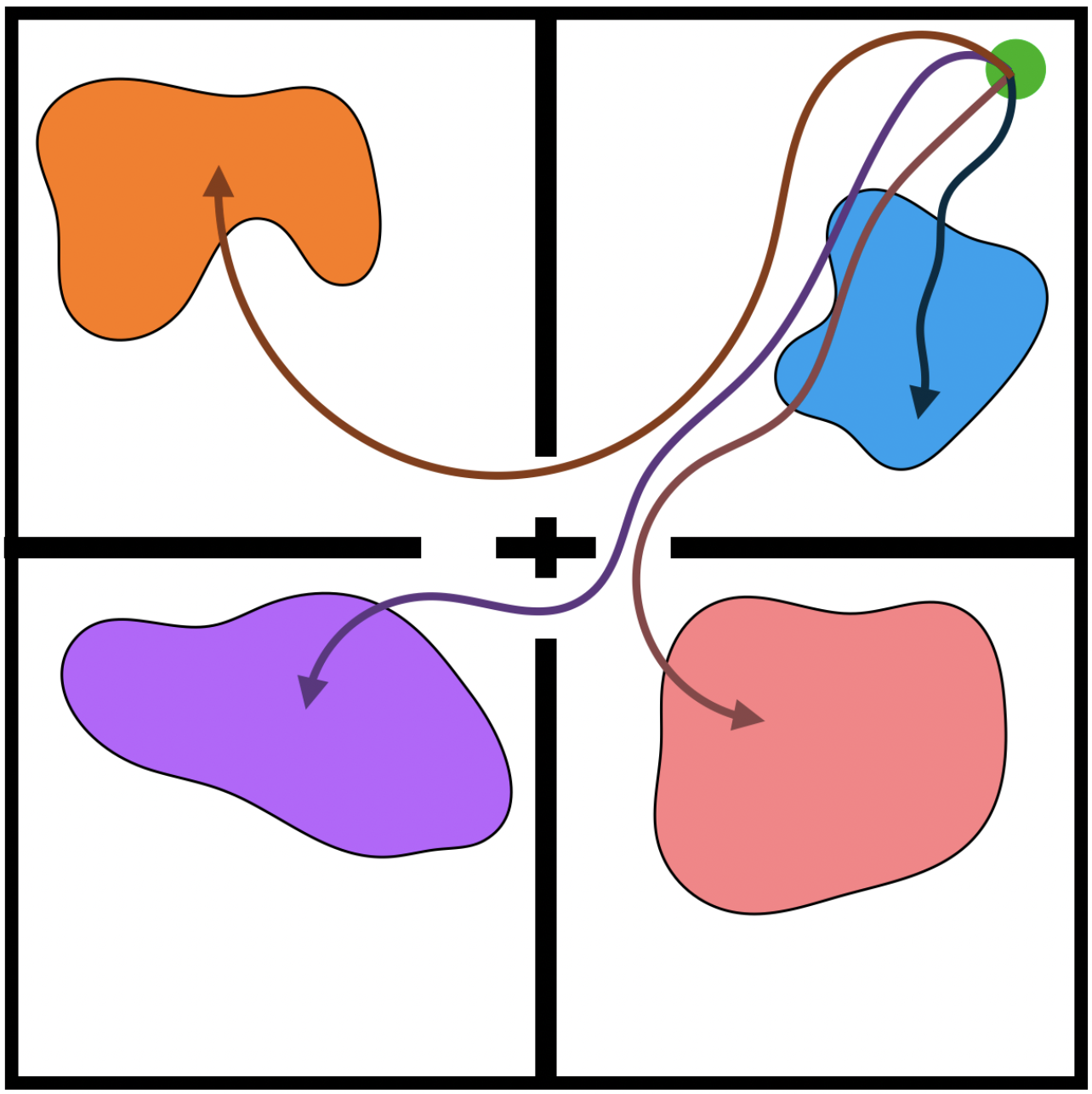
Srinath Mahankali, Zhang-Wei Hong, Ayush Sekhari, Alexander Rakhlin, Pulkit Agrawal ICML, 2024 paper / project page / code / bibtex State-of-the-art exploration by optimizing the agent to achieve randomly sampled latent goals. |

|
Gabriel Margolis, Ge Yang, Kartik Paigwar, Tao Chen, Pulkit Agrawal IJRR, 2024 | RSS, 2022 paper / project page / code / bibtex |
|
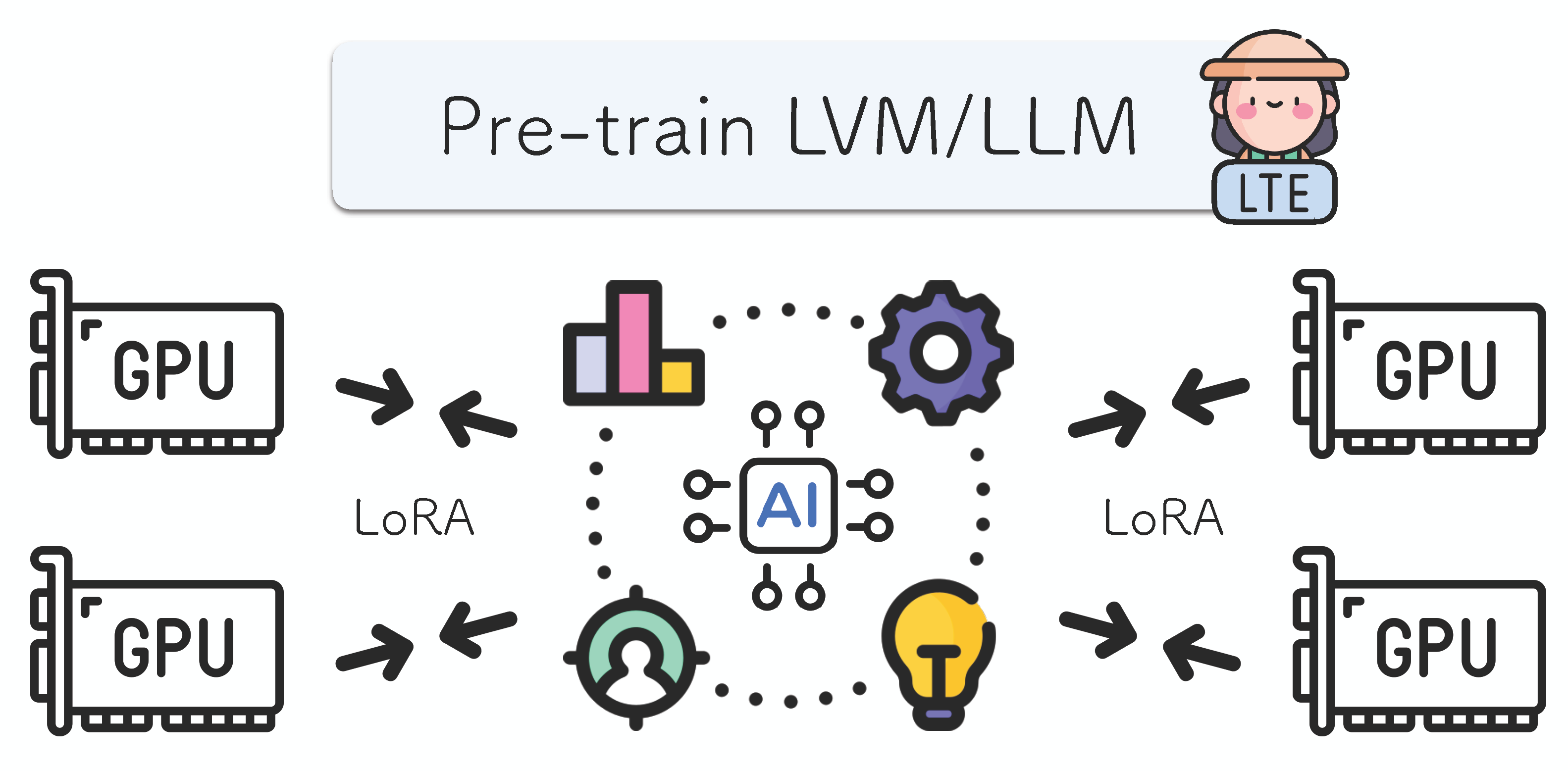
Minyoung Huh, Brian Cheung, Jeremy Bernstein, Phillip Isola, Pulkit Agrawal arXiv, 2024 paper / project page / bibtex A method for parallel training of large models on computers with limited memory. |
|
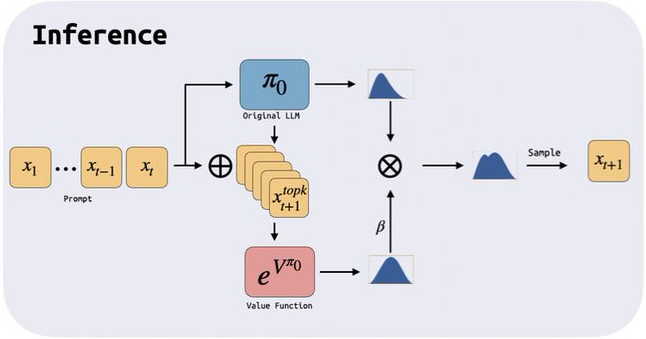
Workshop on Reliable and Responsible Foundation Models, ICLR 2024 (Oral) paper / bibtex Algorithm for inference-time augmentation of Large Language Models. |
|
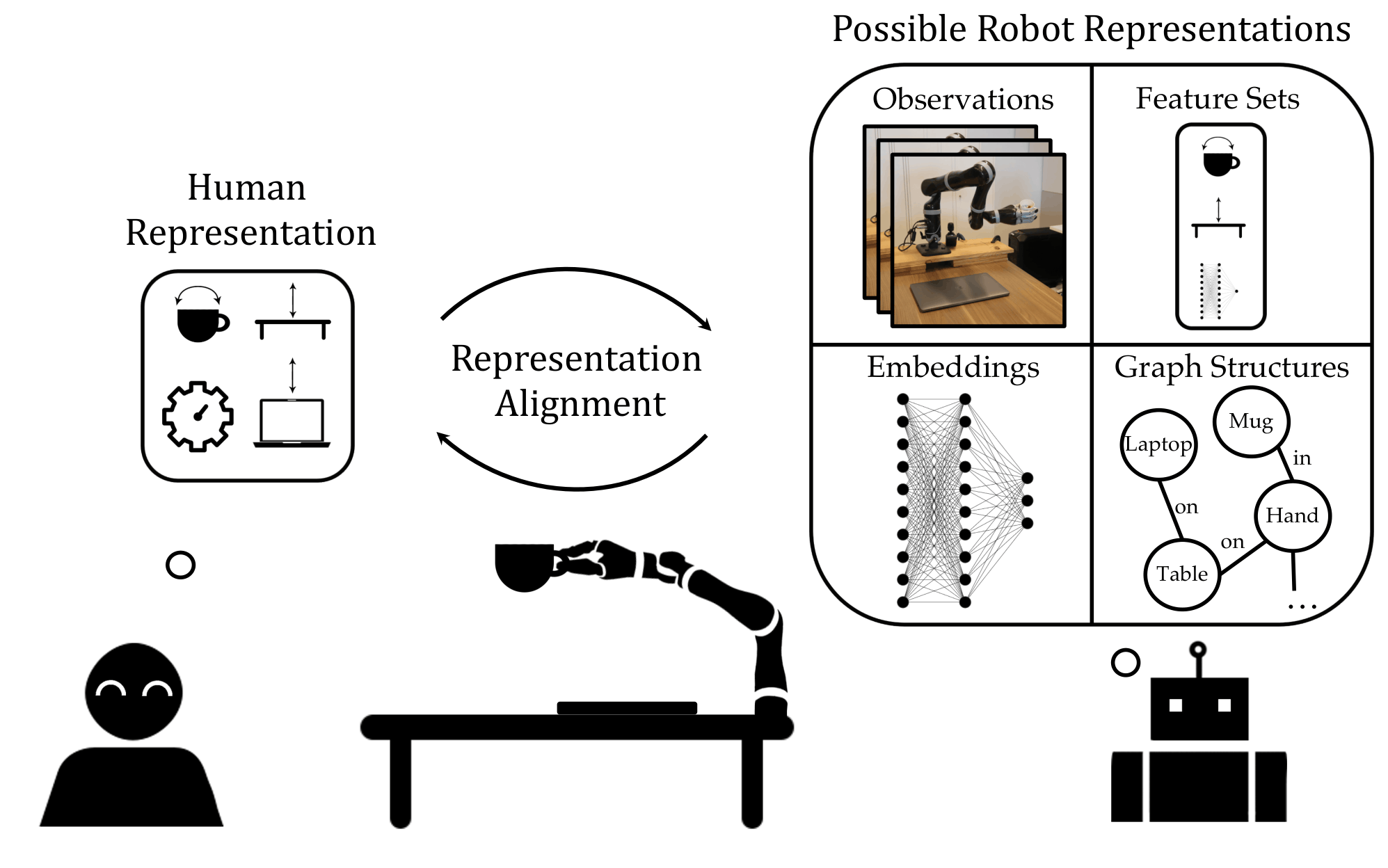
Andreea Bobu, Andi Peng, Pulkit Agrawal, Julie A. Shah, Anca D. Dragan HRI, 2024 paper / bibtex |

|
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal et al. CVPR, 2024 paper / project page / bibtex |

|
Meenal Parakh*, Alisha Fong*, Anthony Simeonov, Abhishek Gupta, Tao Chen, Pulkit Agrawal (*equal contribution) ICRA , 2024 paper / project page / bibtex An LLM-based task planner that can learn new skills opens doors for continual learning. |

|
Tifanny Portela, Gabriel B. Margolis, Yandong Ji, Pulkit Agrawal ICRA, 2024 paper / project page / bibtex Learning to control the force applied by a legged robot's arm for compliant and forceful manipulation. |
|
|
Zhang-Wei Hong, Idan Shenfeld, Tsun-Hsuan Wang, Yung-Sung Chuang, Aldo Pareja, James R. Glass, Akash Srivastava, Pulkit Agrawal ICLR, 2024 paper / code / bibtex |
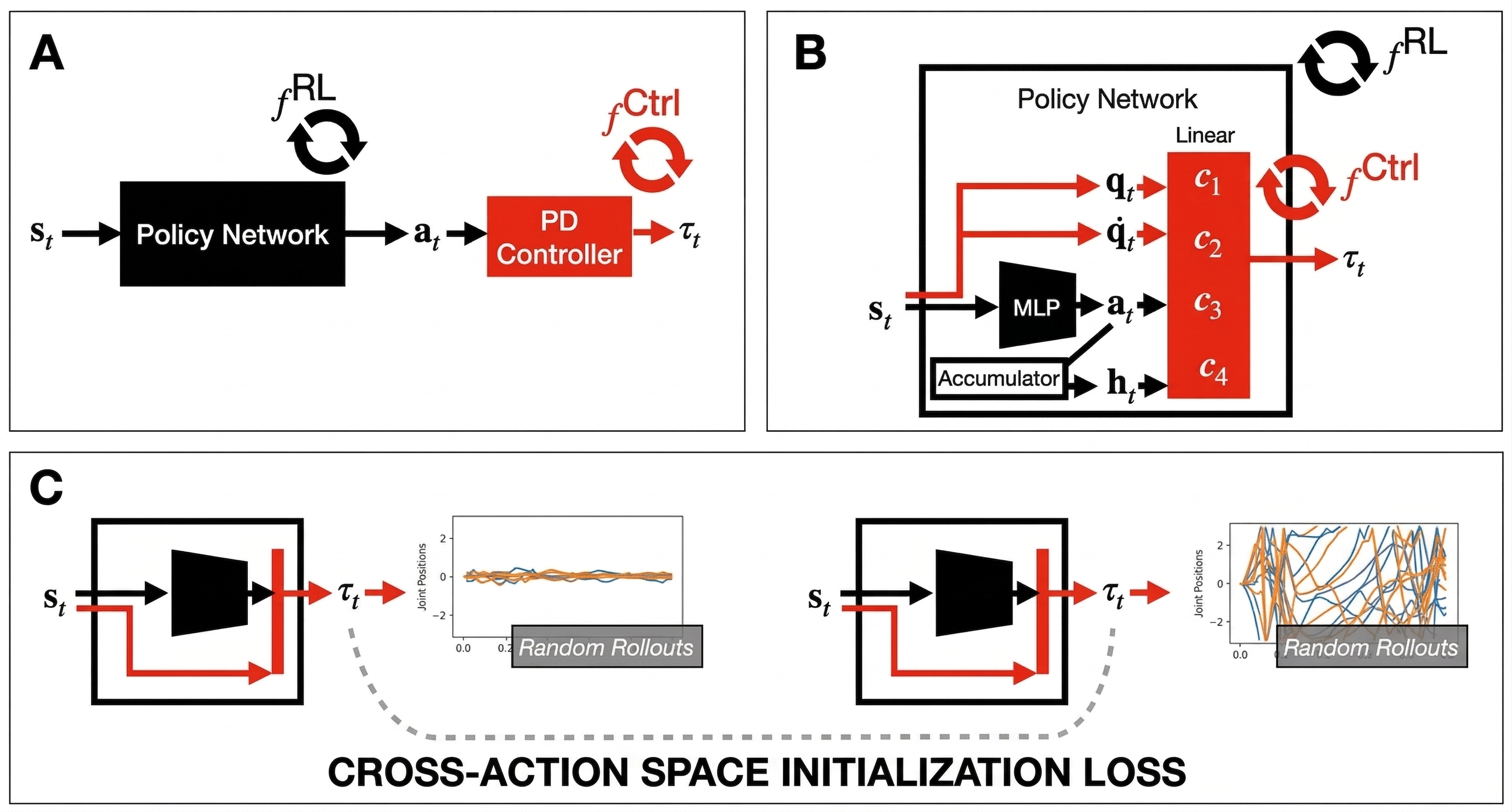
|
Julian Eßer, Gabriel B. Margolis, Oliver Urbann, Sören Kerner, Pulkit Agrawal CoRL, 2024 paper / bibtex |

|
Srinath Mahankali*, Chi-Chang Lee*, Gabriel B. Margolis, Zhang-Wei Hong, Pulkit Agrawal ICRA, 2024 paper / project page / bibtex Principled energy minimization increases robot's agility. |

|
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Pulkit Agrawal IROS, 2024 paper / project page / code / bibtex Learning complex assembly skills from few human demonstrations. |
|
Jaedong Hwang, Zhang-Wei Hong, Eric R Chen, Akhilan Boopathy, Pulkit Agrawal, Ila R Fiete TMLR, 2024 paper / bibtex |

|
Changling Li, Zhang-Wei Hong, Pulkit Agrawal, Divyansh Garg, Joni Pajarinen RLC, 2024 paper / bibtex |
|
Daniel Yang, Davin Tjia, Jacob Berg, Dima Damen, Pulkit Agrawal, Abhishek Gupta ICRA, 2024 paper / project page / code / bibtex Learning reward functions from videos of human demonstrations. |

|
Rubén Castro Ornelas, Tomás Cantú, Isabel Sperandio, Alexander H. Slocum, Pulkit Agrawal ICRA, 2024 paper / project page / bibtex Robotic finger designed to perform every day tasks. |
|
Tao Chen, Megha Tippur, Siyang Wu, Vikash Kumar, Edward Adelson, Pulkit Agrawal Science Robotics, 2023 paper / project page / bibtex A real-time controller that dynamically reorients complex and novel objects by any amount using a single depth camera. |
|
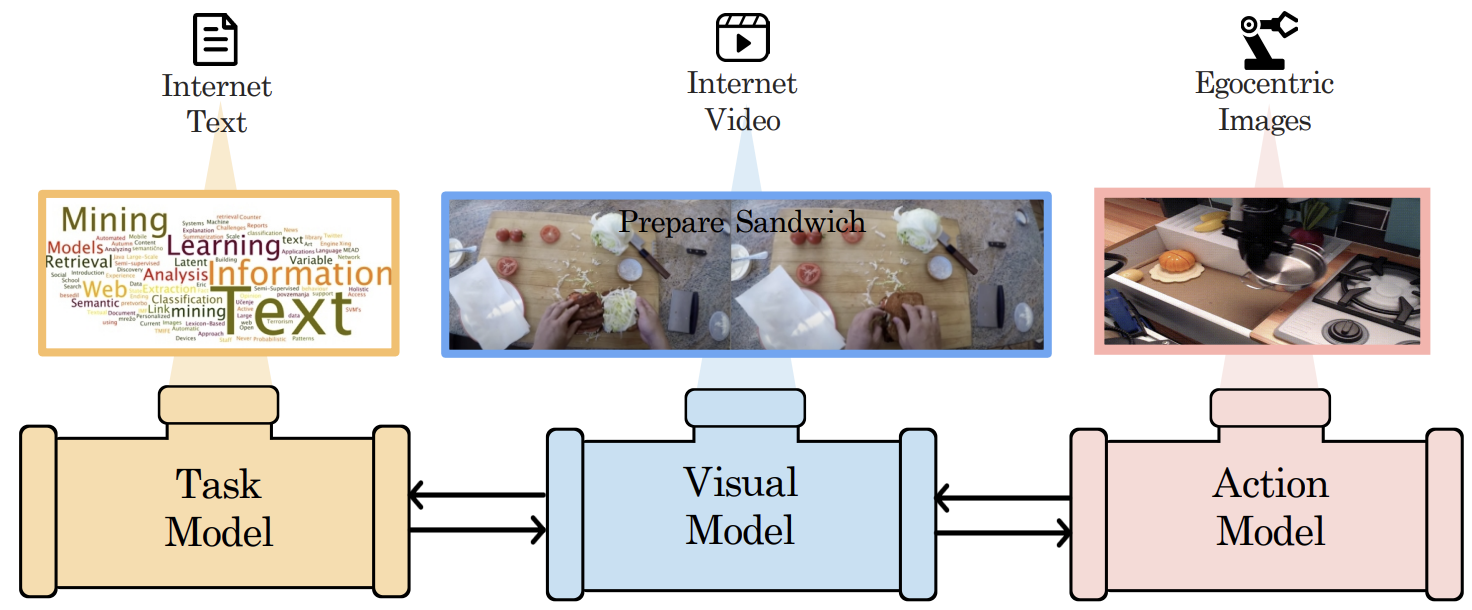
|
Anurag Ajay*, Seungwook Han*, Yilun Du*, Shuang Li, Abhi Gupta, Tommi Jaakkola, Josh Tenenbaum, Leslie Kaelbling, Akash Srivastava, Pulkit Agrawal (* equal contribution) NeurIPS, 2023 paper / project page / bibtex Composing existing foundation models operating on different modalities to solve long-horizon tasks. |
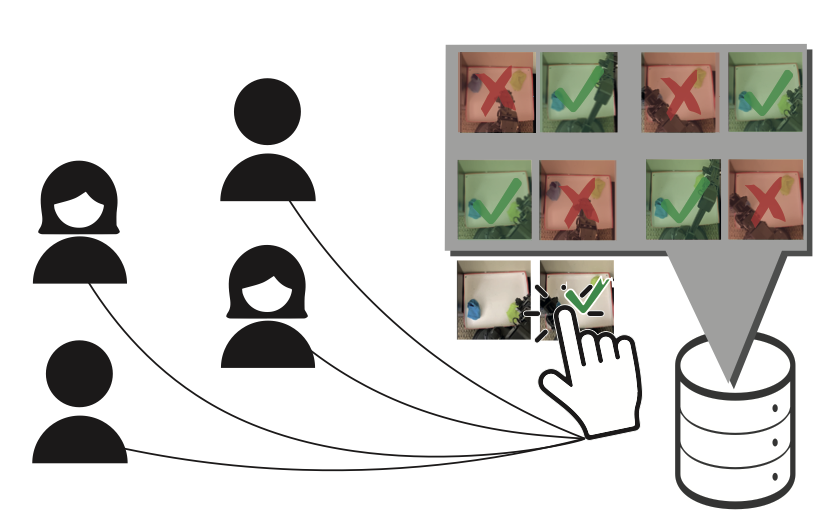
|
Marcel Torne, Max Balsells, Zihan Wang, Samedh Desai, Tao Chen, Pulkit Agrawal, Abhishek Gupta NeurIPS, 2023 paper / project page / code / bibtex Method for guiding goal-directed exploration with asynchronous human feedback. |
|
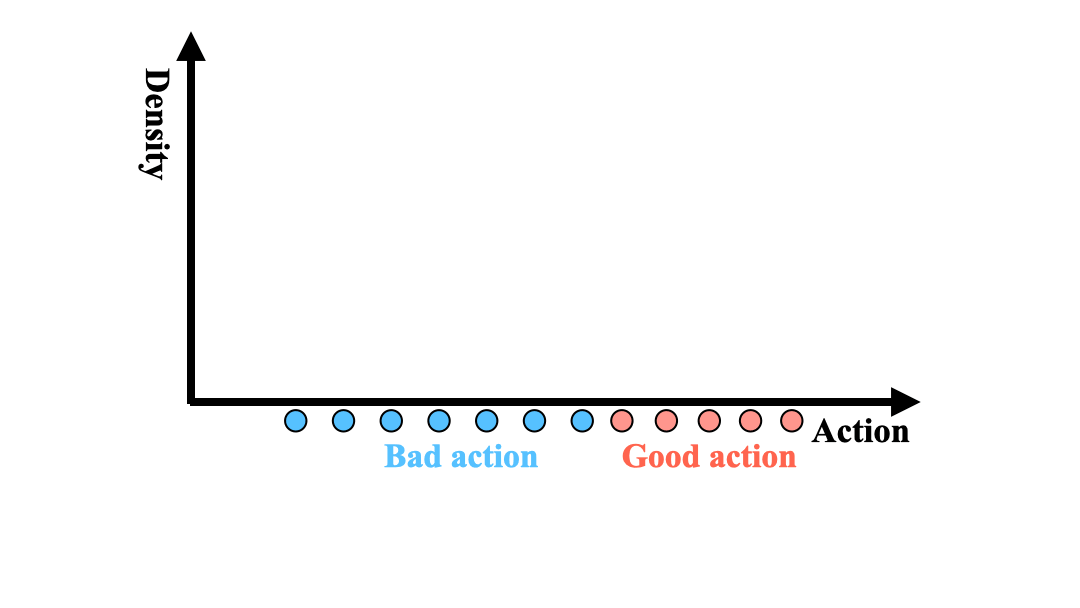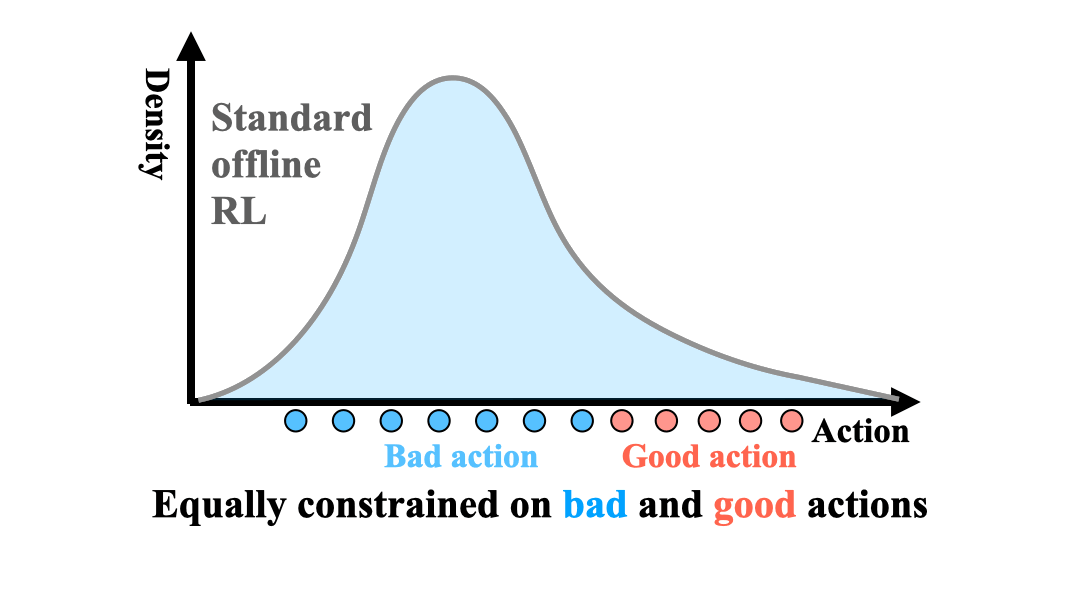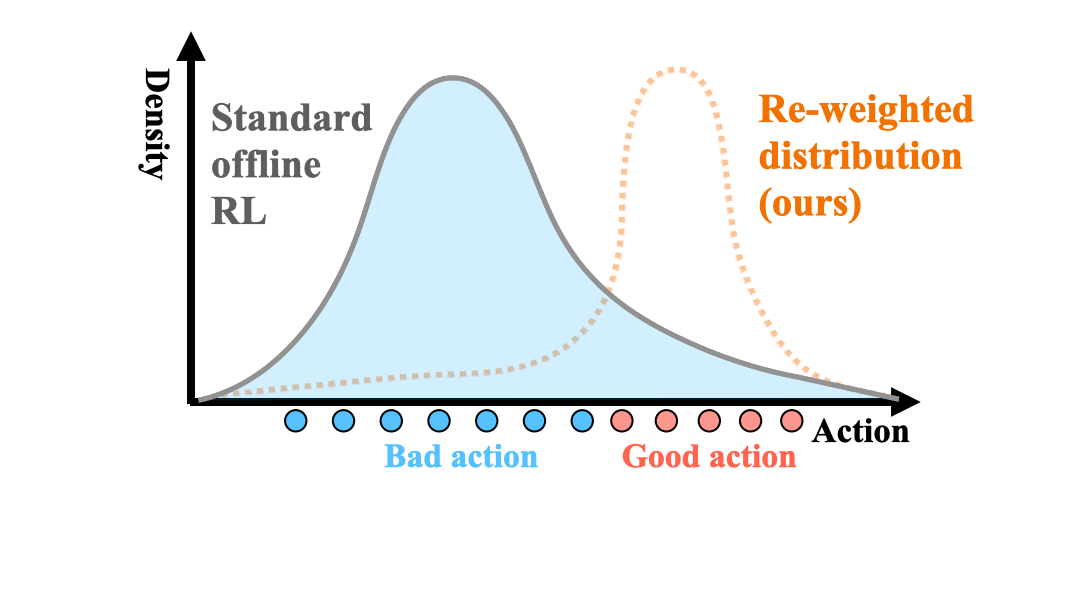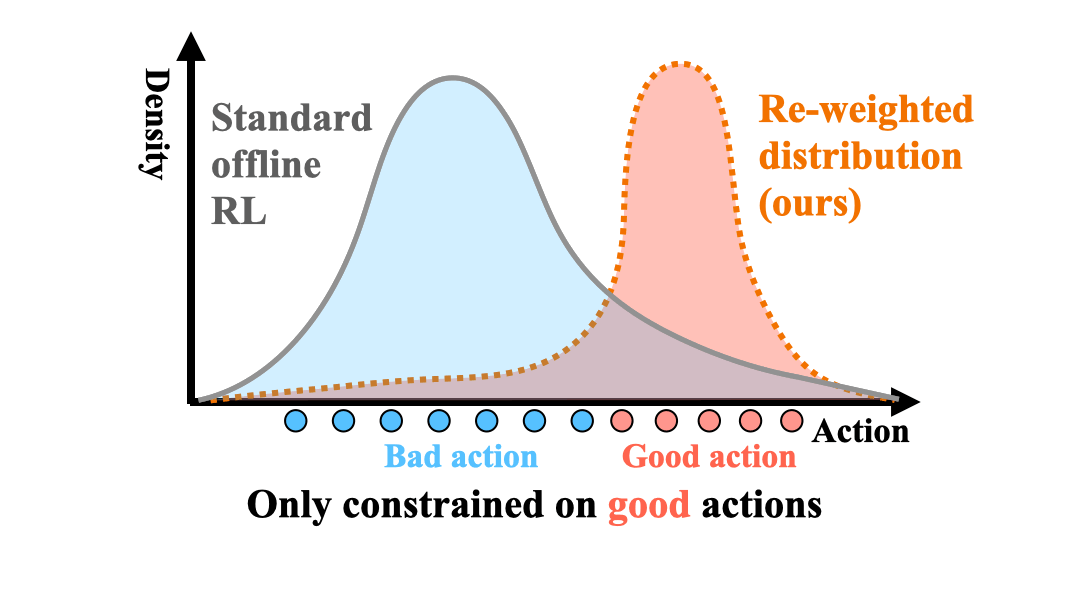
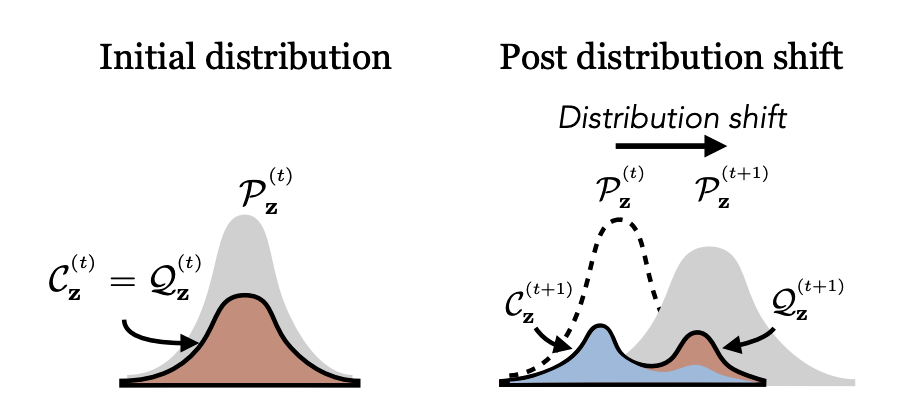
Zhang-Wei Hong, Aviral Kumar, Sathwik Karnik, Abhishek Bhandwaldar, Akash Srivastava, Joni Pajarinen, Romain Laroche, Abhishek Gupta, Pulkit Agrawal NeurIPS, 2023 paper / bibtex / code Optimizing the sampling distribution enables offline RL to learn a good policy in skewed datasets primarily composed of sub-optimal trajectories. |
|
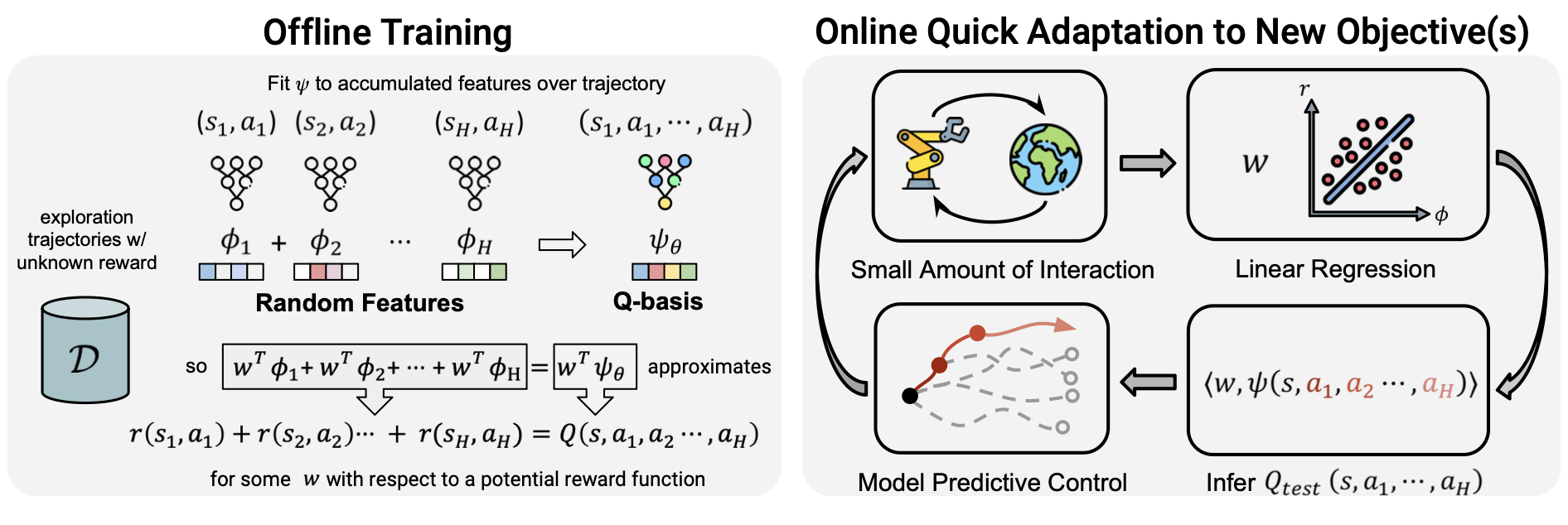
Boyuan Chen, Chuning Zhu, Pulkit Agrawal, Kaiqing Zhang, Abhishek Gupta NeurIPS, 2023 paper / bibtex |

|
Anthony Simeonov, Ankit Goyal*, Lucas Manuelli*, Lin Yen-Chen, Alina Sarmiento, Alberto Rodriguez, Pulkit Agrawal**, Dieter Fox** (*equal contribution, **equal advising) CoRL, 2023 paper / project page / code / bibtex Relational rearrangement with multi-modal placing and generalization over scene layouts via diffusion and local scene conditioning. |

|
Gabriel B. Margolis, Xiang Fu, Yandong Ji, Pulkit Agrawal Conference on Robot Learning (CoRL), 2023 paper / project page / bibtex Learn to perceive physical properties of terrains in front of the robot (i.e., a digital twin). |

|
Yanwei Wang, Ching-Yun Ko, Pulkit Agrawal IROS 2023, NeurIPS 2022 Workshop paper / code / project page / bibtex Learning to navigate by moving the camera across random images. |
|
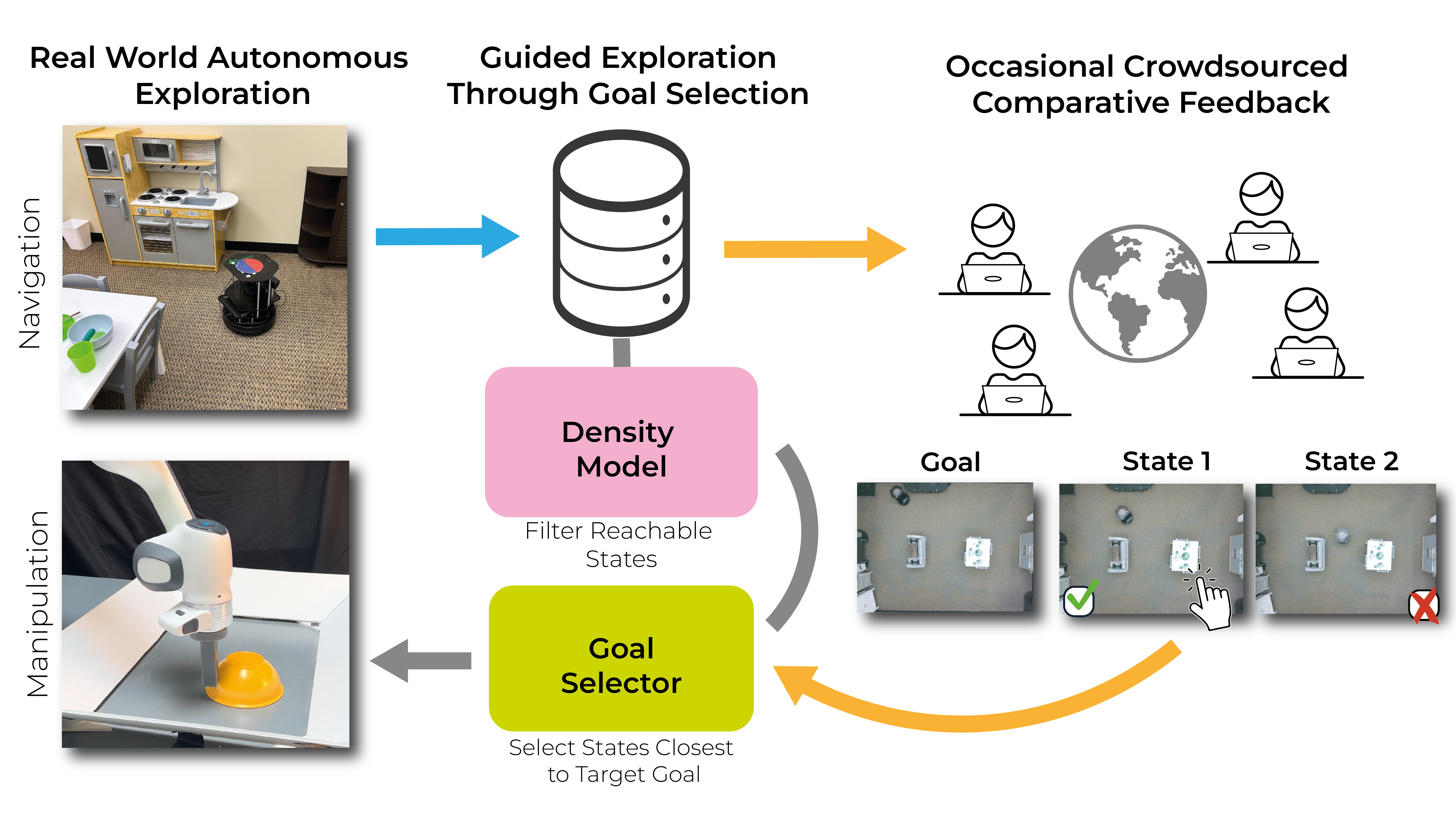
Max Balsells*, Marcel Torne*, Zihan Wang, Samedh Desai, Pulkit Agrawal, Abhishek Gupta CoRL, 2023 paper / bibtex Leveraging crowdsourced non-expert human feedback to guide exploration in robot policy learning. |
|
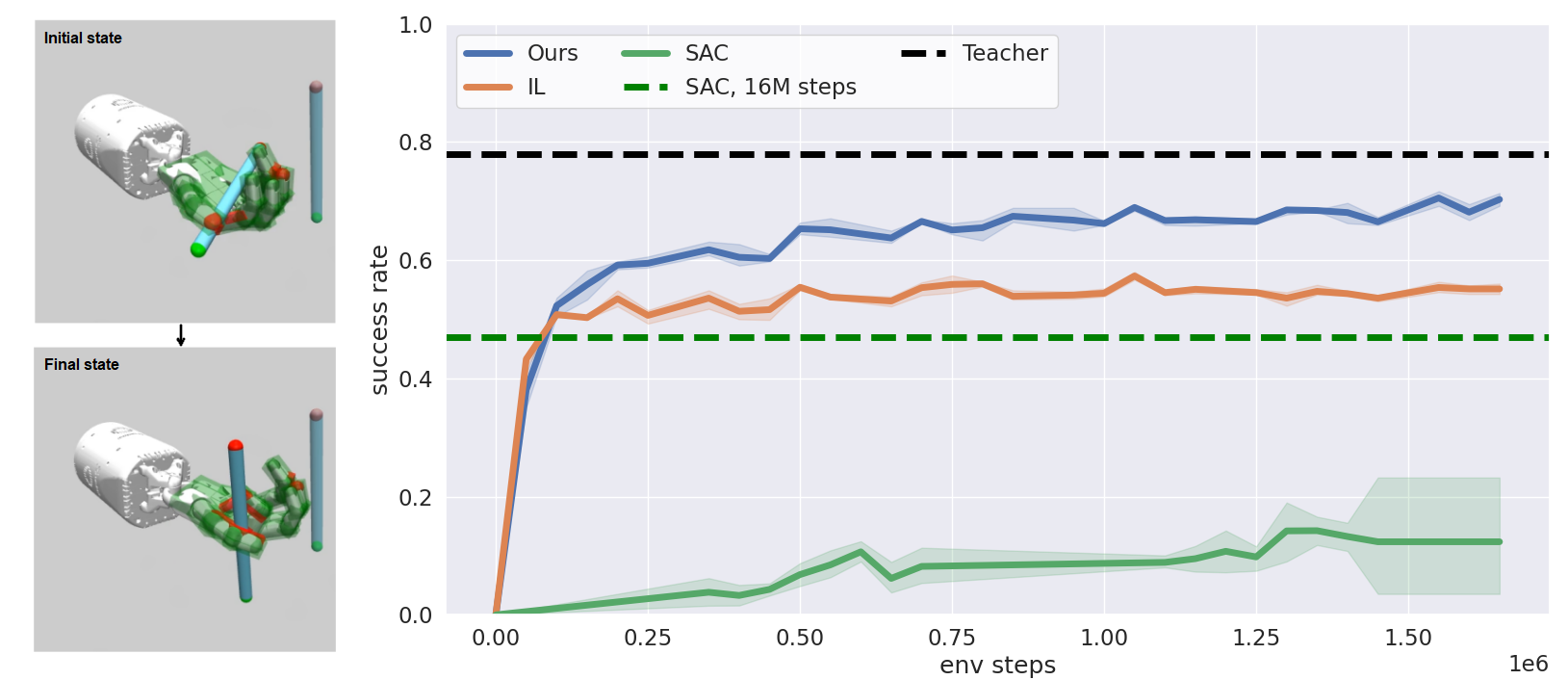
Idan Shenfeld, Zhang-Wei Hong, Aviv Tamar, Pulkit Agrawal ICML, 2023 paper / code / project page / bibtex An algorithm for automatically balancing learning from teacher's guidance and task reward. |
|
Minyoung Huh, Brian Cheung, Pulkit Agrawal, Phillip Isola International Conference on Machine Learning (ICML), 2023 paper / website / code / bibtex A set of suggestions that simplifies training of vector quantization layers. |
|
Zechu Li*, Tao Chen*, Zhang-Wei Hong, Anurag Ajay, Pulkit Agrawal (* indicates equal contribution) ICML, 2023 paper / code / bibtex Scaling Q-learning algorithms to 10K+ workers. |
|
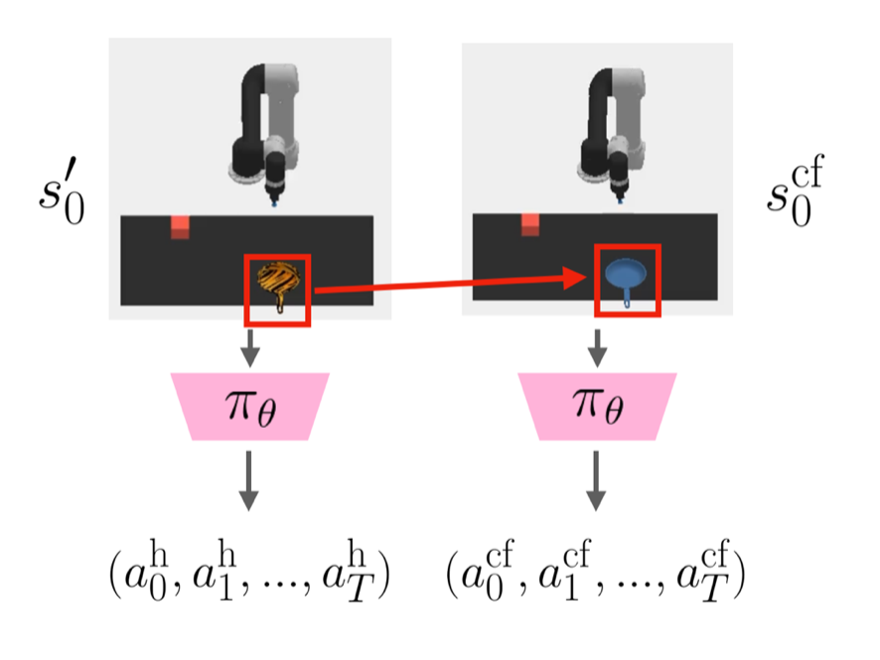
Andi Peng, Aviv Netanyahu, Mark Ho, Tianmin Shu, Andreea Bobu, Julie Shah, Pulkit Agrawal ICML, 2023 paper / project page / bibtex A step towards using counterfactuals for improving policy adaptation. |
|
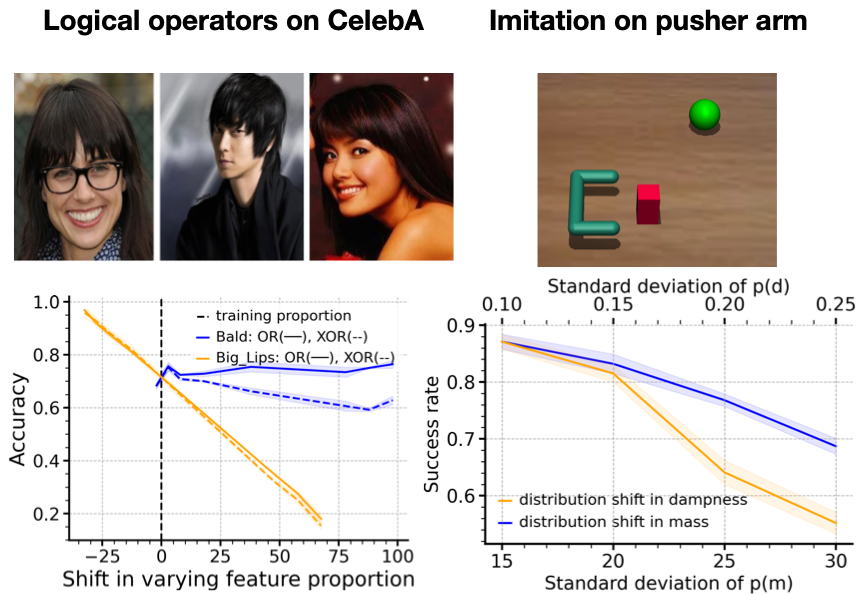
Max Simchowitz*, Anurag Ajay*, Pulkit Agrawal, Akshay Krishnamurthy (* equal contribution) ICML, 2023 paper / bibtex In-distribution error for certain features predicts their out-of-distribution sensitivity. |

|
Yandong Ji*, Gabriel B. Margolis*, Pulkit Agrawal (*equal contribution) International Conference on Robotics and Automation (ICRA), 2023 paper / project page / bibtex Press: TechCrunch, IEEE Spectrum, NBC Boston, Insider, Yahoo!News, MIT News Dynamic legged object manipulation on diverse terrains with onboard compute and sensing. |
|
Sameer Pai*, Tao Chen*, Megha Tippur*, Edward Adelson, Abhishek Gupta†, Pulkit Agrawal† (*equal contribution, † equal advising) International Conference on Robotics and Automation (ICRA), 2023 paper / project page / bibtex Localize, identify, and fetch a target object in the dark with tactile sensors. |
|
|
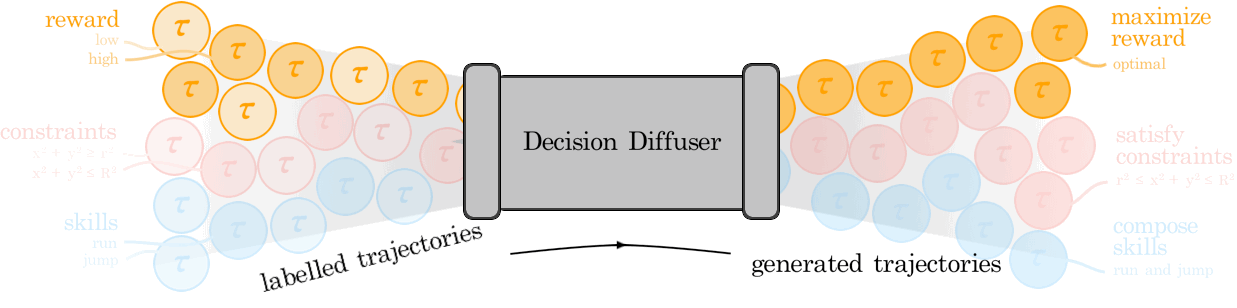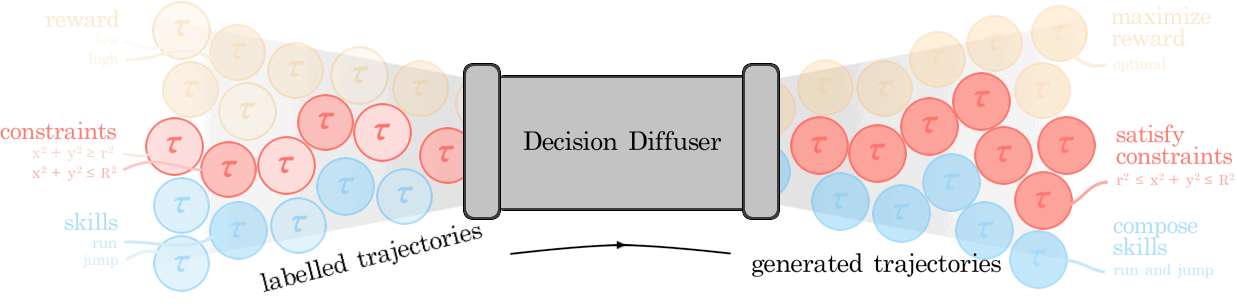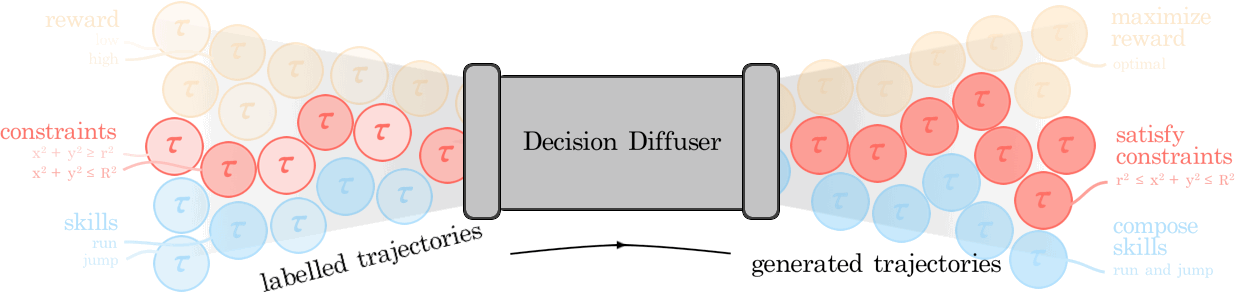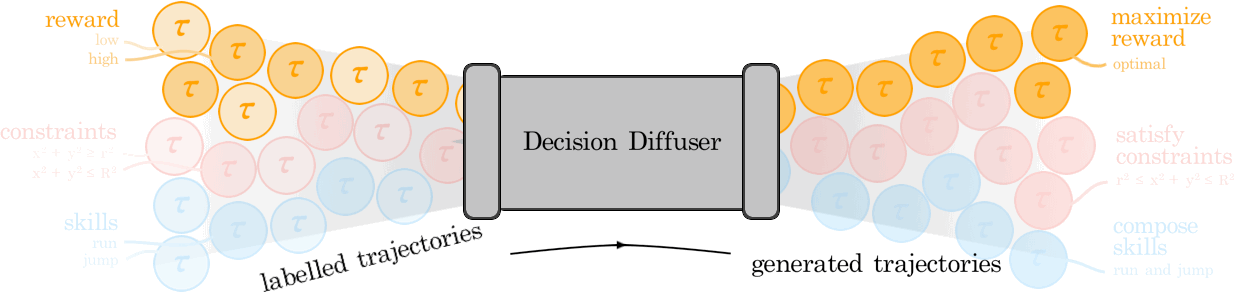
Anurag Ajay*, Yilun Du*, Abhi Gupta*, Josh Tenenbaum, Tommi Jaakkola, Pulkit Agrawal (*equal contribution) ICLR, 2023 (Oral) paper / project page / bibtex Return conditioned generative models offer a powerful alternative to temporal-difference learning for offline decision making and reasoning with constraints. |
|
|
Aviv Netanyahu*, Abhishek Gupta*, Max Simchowitz, Kaiqing Zhang, Pulkit Agrawal (*equal contribution) ICLR, 2023 paper / bibtex Transductive reparameterization converts out-of-support generalization problem into out-of-combination generalization which is possible under low-rank style conditions. |
|
|
Zhang-Wei Hong, Pulkit Agrawal, Remi Tachet des Combes, Romain Laroche ICLR, 2023 paper / bibtex Return reweighted sampling of trajectories enables offline RL algorithms to work with skewed datasets. |
|
|
Minyoung Huh, Hossein Mobahi, Richard Zhang, Brian Cheung, Pulkit Agrawal, Phillip Isola Transactions of Machine Learning Research (TMLR), 2023 paper / website / bibtex Deeper Networks find simpler solutions! Also learn why ResNets overcome the challenges associated with very deep networks. |
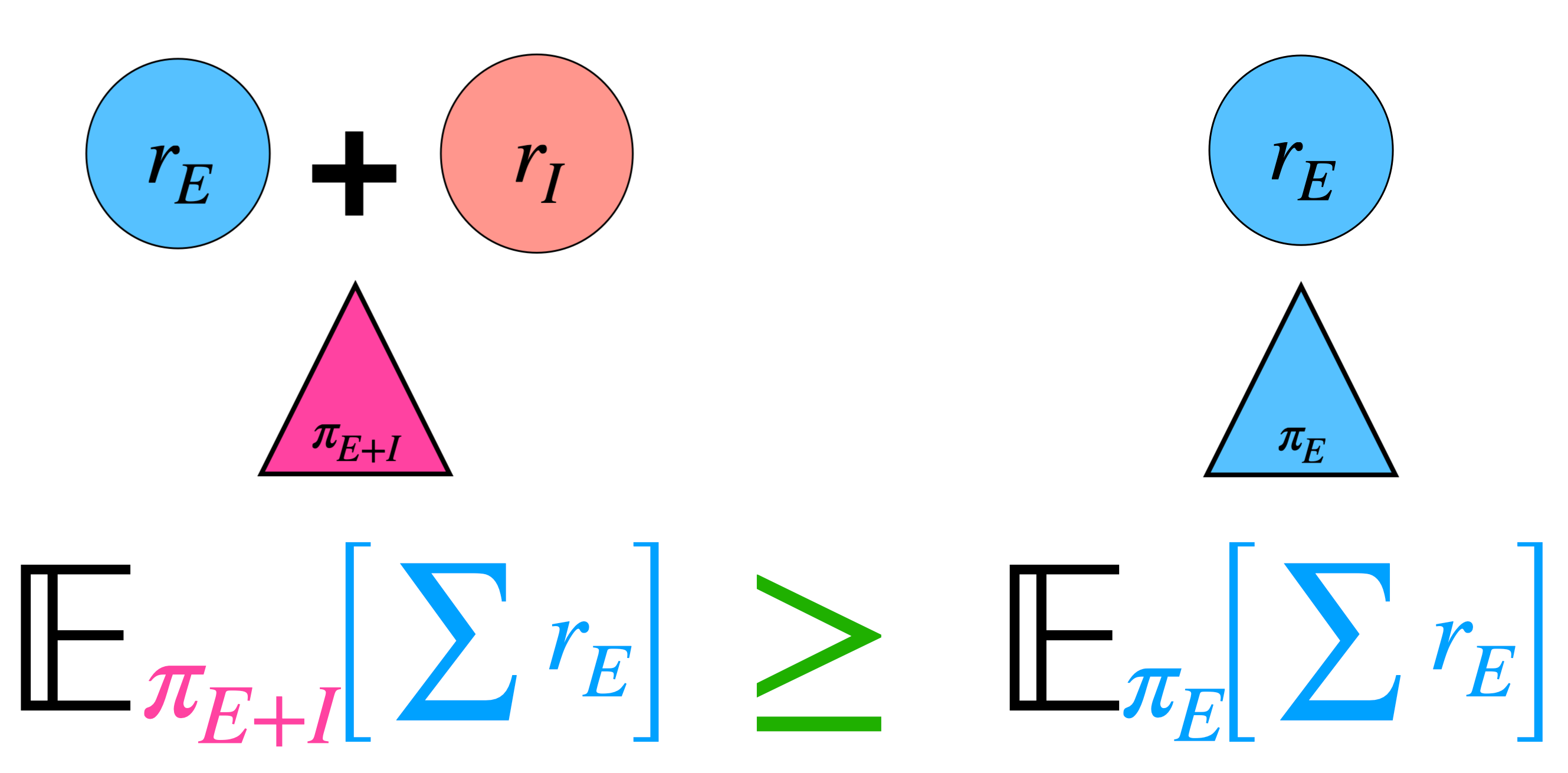
|
Eric Chen*, Zhang-Wei Hong*, Joni Pajarinen, Pulkit Agrawal (*equal contribution) NeurIPS, 2022 paper / project page / bibtex Press: MIT News Method that automatically balances exploration bonus or curiosity against task rewards leading to consistent performance improvement. |

|
Anthony Simeonov*, Yilun Du*, Lin Yen-Chen, Alberto Rodriguez, Leslie P. Kaelbling, Tomás Lozano-Peréz, Pulkit Agrawal (*equal contribution) CoRL, 2022 paper / project page / code / bibtex Learning relational tasks with a few demonstrations in a way that generalizes to new configurations of objects. |

|
Gabriel B. Margolis, Pulkit Agrawal CoRL, 2022 (Oral) paper / code / project page / bibtex One learned policy embodies many dynamic behaviors useful for different tasks. |
|
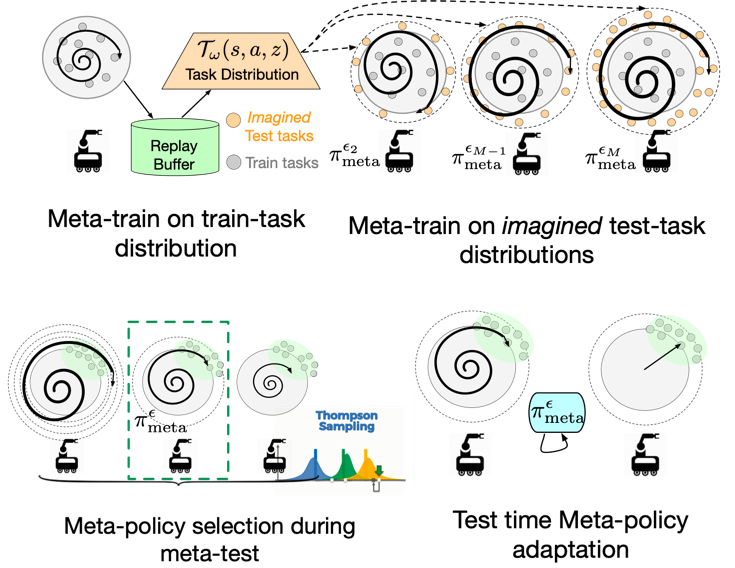
Anurag Ajay*, Abhishek Gupta*, Dibya Ghosh, Sergey Levine, Pulkit Agrawal (*equal contribution) NeurIPS, 2022 paper / project page / bibtex Being adaptive instead of being robust results in faster adaption to out-of-distribution tasks. |
|
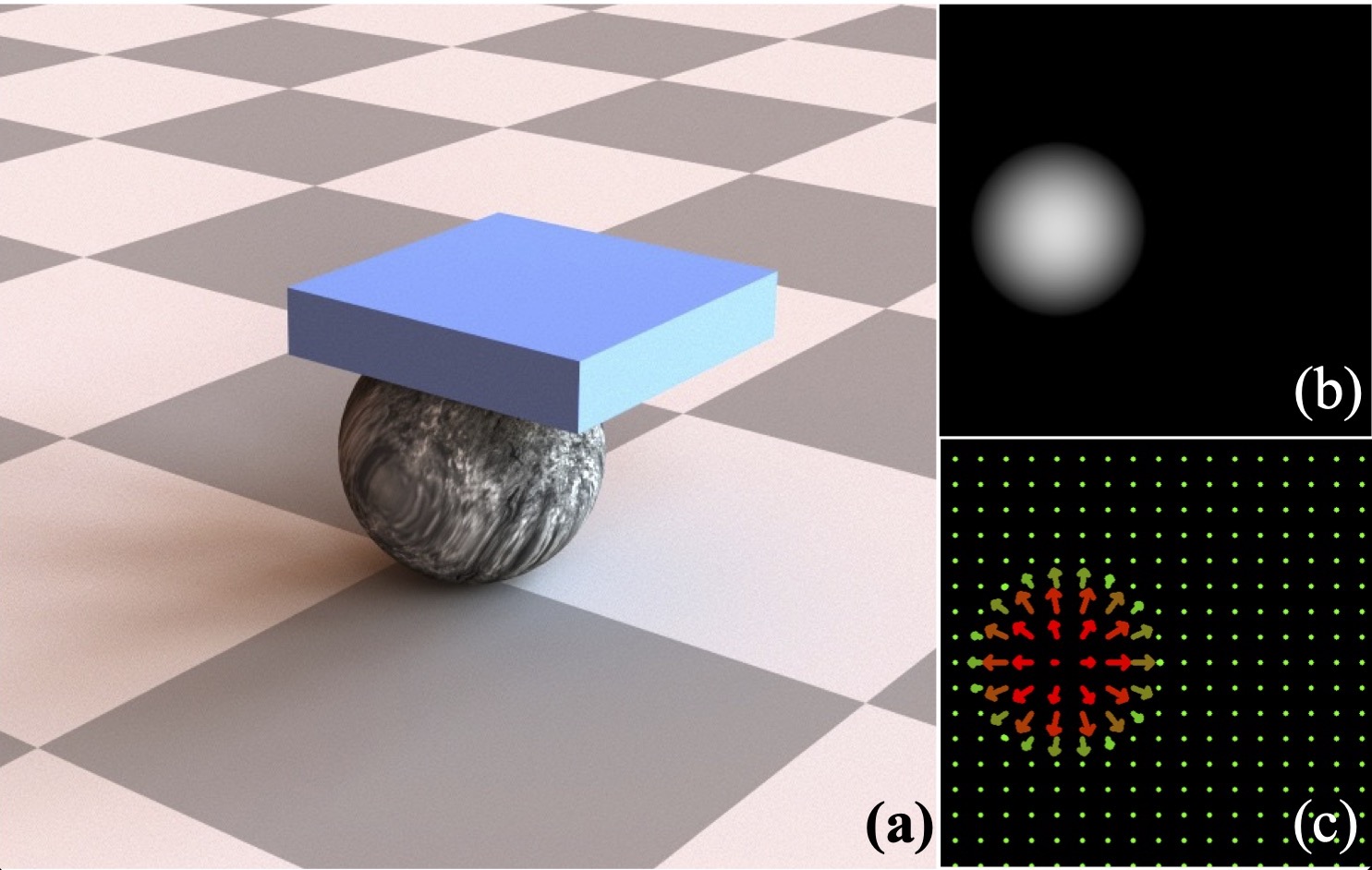
Jie Xu, Sangwoon Kim, Tao Chen, Alberto Rodriguez, Pulkit Agrawal, Wojciech Matusik, Shinjiro Sueda CoRL, 2022 paper / Code coming soon / project page / bibtex Tactile Simulator for complex shapes training on which transfers to real-world. |
|
Haokuan Luo, Albert Yue, Zhang-Wei Hong, Pulkit Agrawal IROS, 2022 paper / code / bibtex State-of-the-art Performance on Habitat Navigation Challenge without any machine learning for navigation. |

|
Anthony Simeonov*, Yilun Du*, Andrea Tagliasacchi, Joshua B. Tenenbaum, Alberto Rodriguez, Pulkit Agrawal**, Vincent Sitzmann** (*equal contribution, order determined by coin flip. **equal advising) ICRA, 2022 paper / website and code / bibtex An SE(3) Equivariant method for specifiying and finding correspondences which enables data efficient object manipulation. |

|
Lara Zlokapa, Yiyue Luo, Jie Xu, Michael Foshey, Kui Wu, Pulkit Agrawal, Wojciech Matusik ICRA, 2022 paper / website / bibtex A method for users to easily design a variety of robotic manipulators with integrated tactile sensors. |

|
Richard Li, Carlos Esteves, Ameesh Makadia, Pulkit Agrawal ICRA, 2022 paper / bibtex Predicting contact points with a CVAE and plane segmentation improves object generalization and handles multimodality. |
|
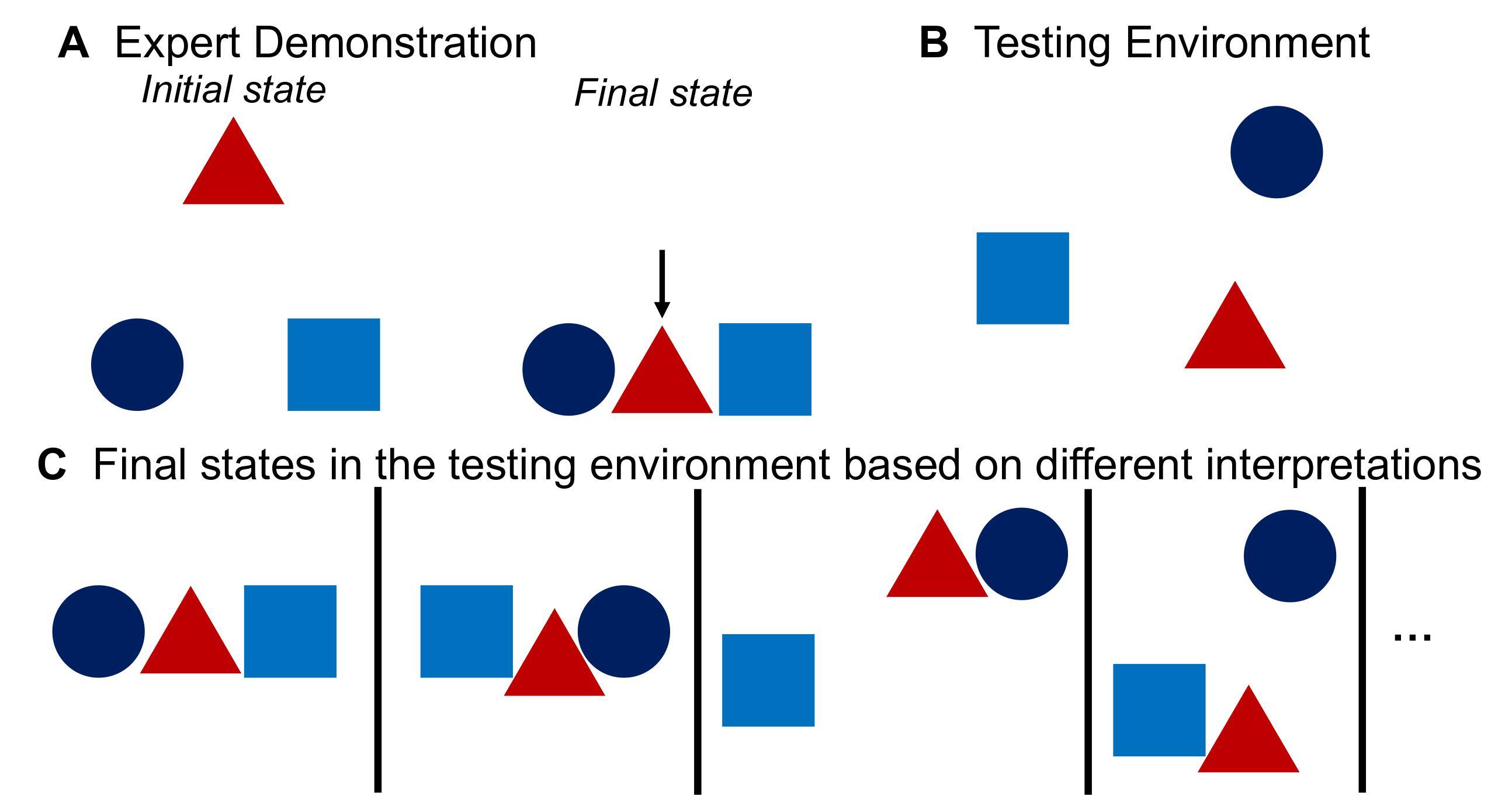
Aviv Netanyahu*, Tianmin Shu*, Joshua B. Tenenbaum, Pulkit Agrawal ICML, 2022 paper / bibtex Graph-based one-shot reward learning via active learning for object rearrangement tasks. |
|
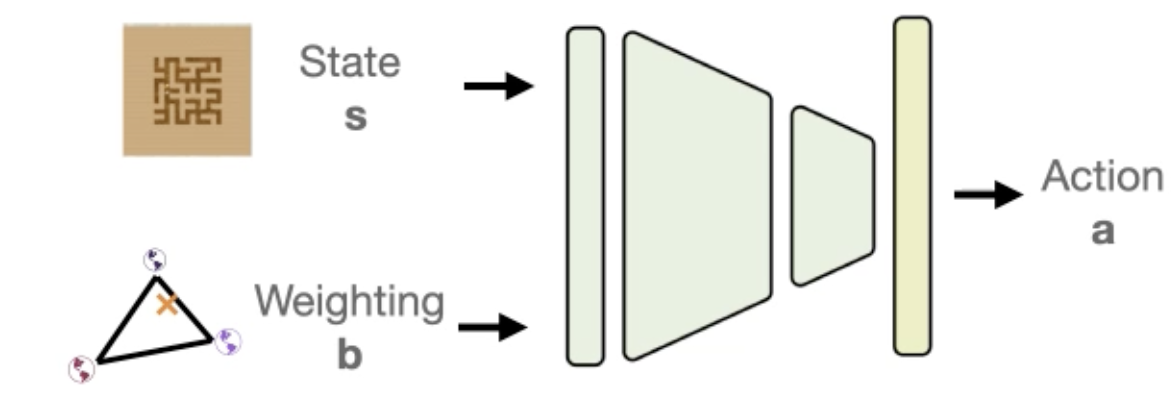
Dibya Ghosh, Anurag Ajay, Pulkit Agrawal, Sergey Levine ICML, 2022 paper / bibtex Online adaptation of offline RL policies using evaluation data improves performance. |
|
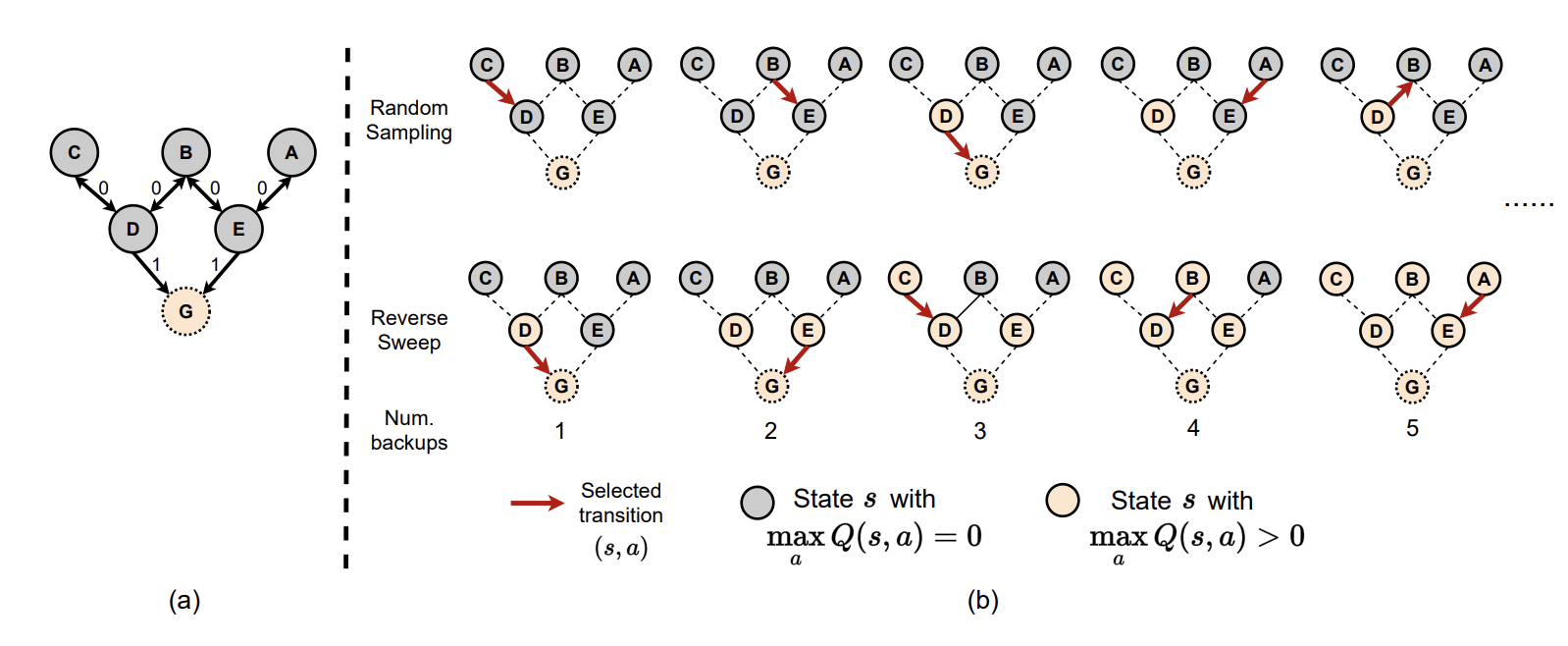
Zhang-Wei Hong, Tao Chen, Yen-Chen Lin, Joni Pajarinen, Pulkit Agrawal ICLR, 2022 paper / bibtex Sampling data from the replay buffer informed by topological structure of the state space improves performance. |
|
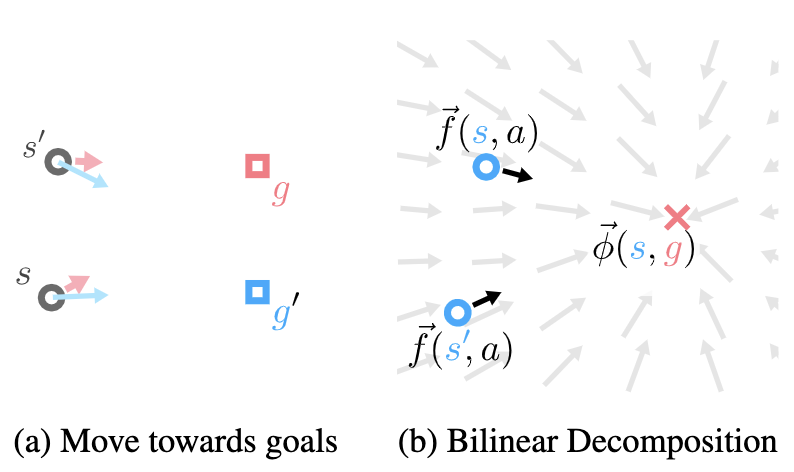
Zhang-Wei Hong*, Ge Yang*, Pulkit Agrawal (*equal contribution) ICLR, 2022 paper / bibtex Bilinear decomposition of the Q-value function improves generalization and data efficiency. |
|
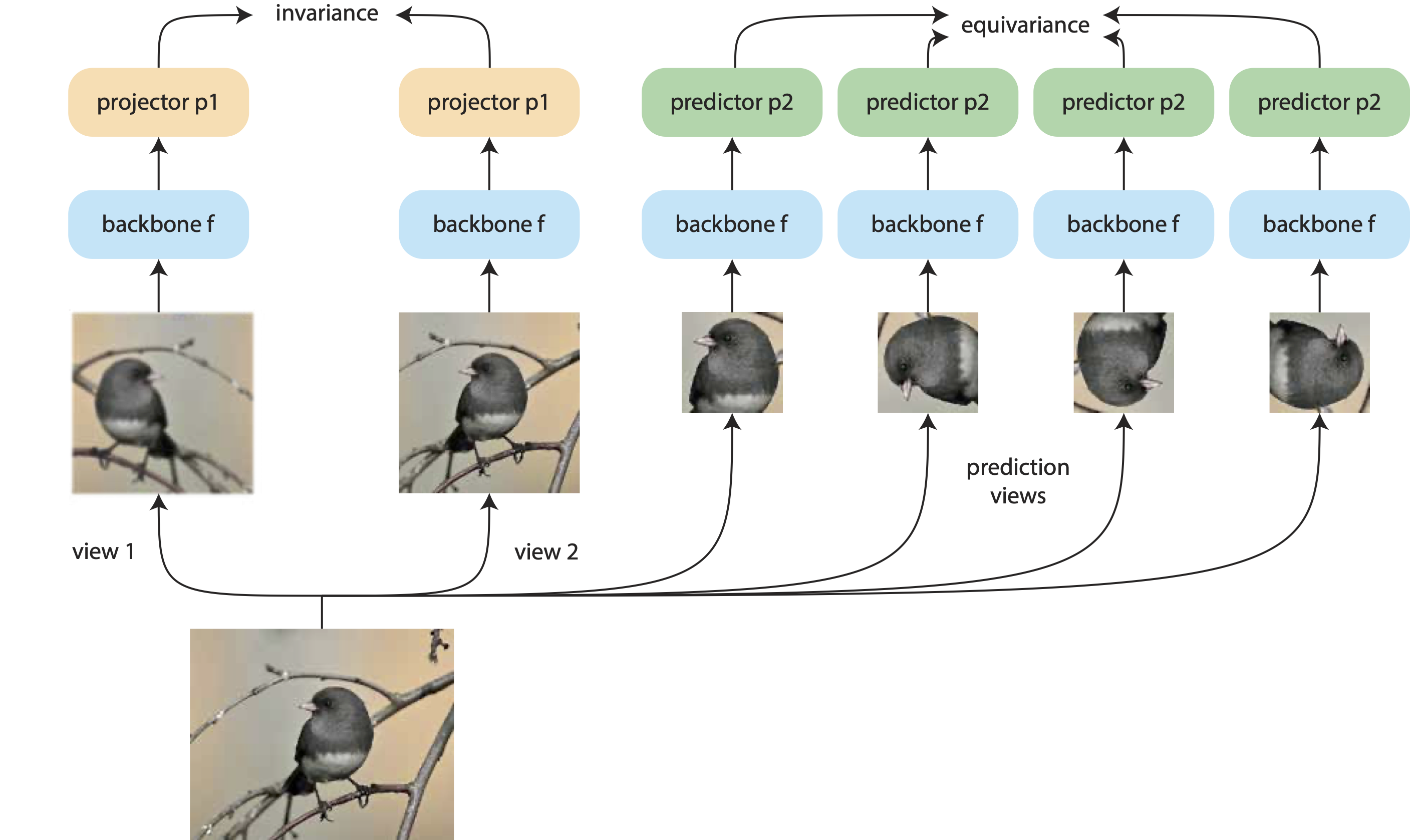
Rumen Dangovski, Li Jing, Charlotte Loh, Seungwook Han, Akash Srivastava, Brian Cheung, Pulkit Agrawal, Marin Soljacic ICLR , 2022 paper / bibtex Study revealing complementarity of invariance and equivariance in contrastive learning. |
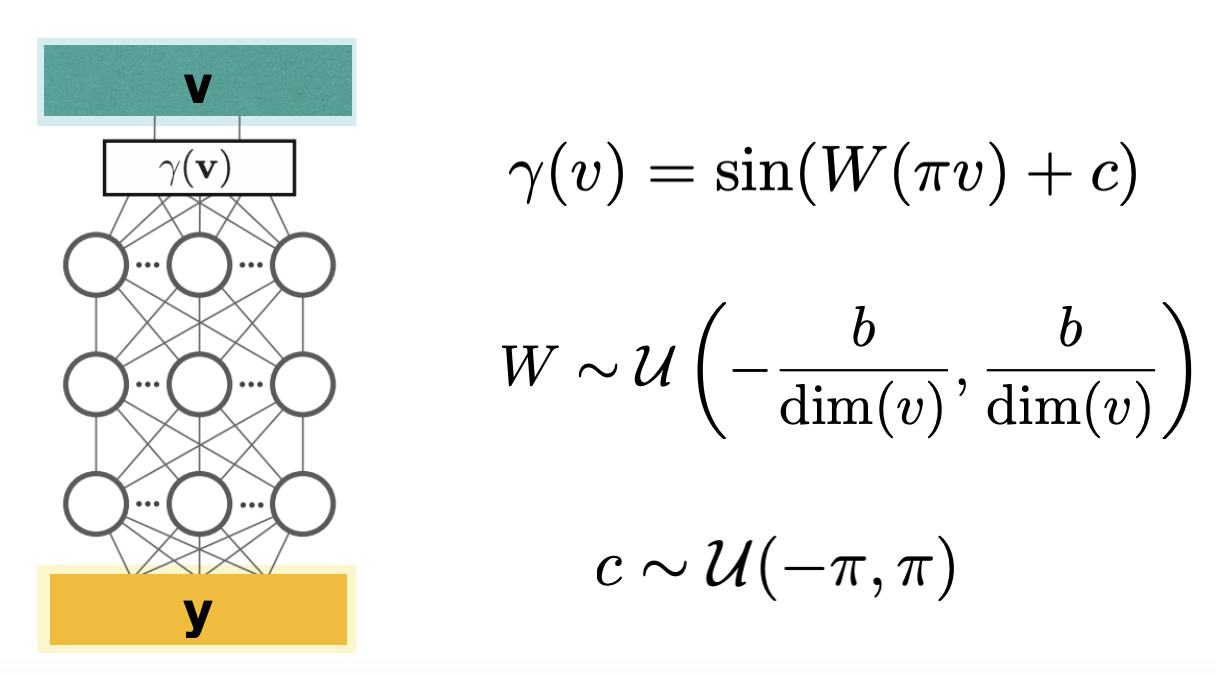
|
Ge Yang*, Anurag Ajay*, Pulkit Agrawal (*equal contribution) ICLR, 2022 paper / bibtex Fourier features improve value estimation and consequently data efficiency. |
|
Tao Chen, Jie Xu, Pulkit Agrawal CoRL, 2021 (Best Paper Award) paper / bibtex / project page Press: MIT News A framework for general in-hand object reorientation. |

|
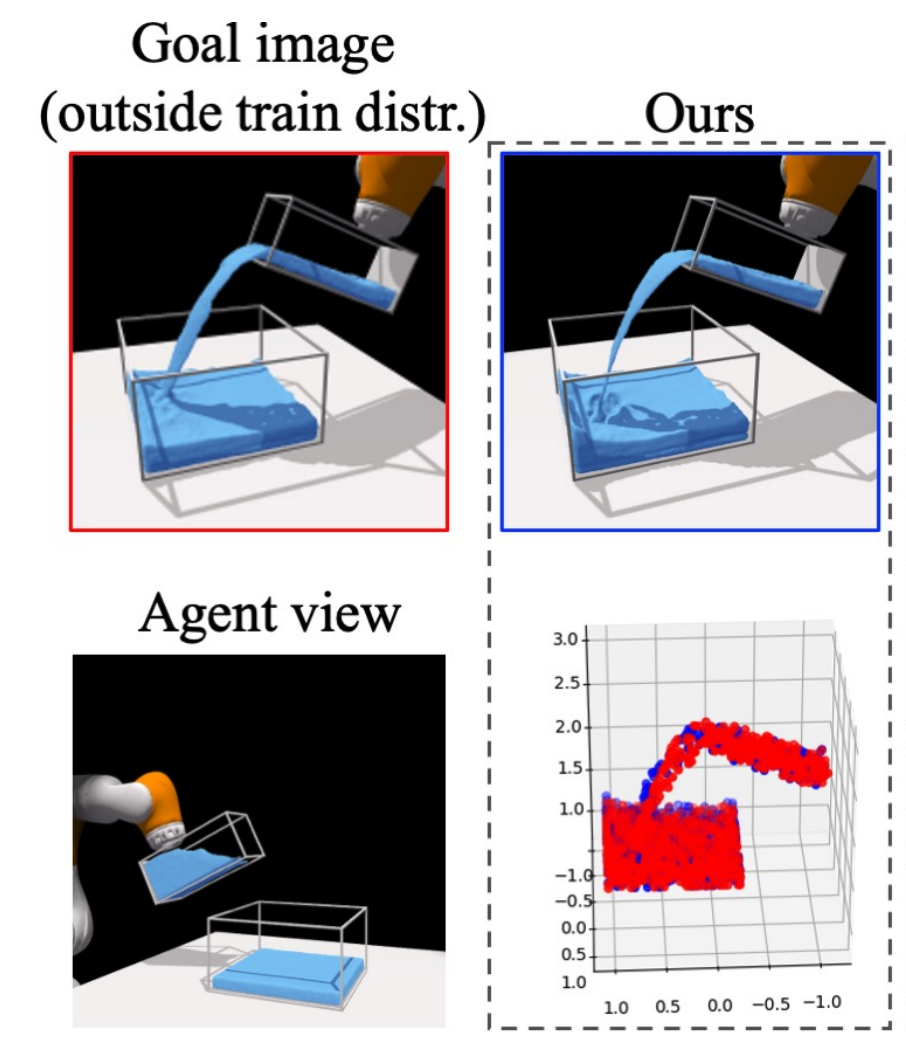
Gabriel Margolis, Tao Chen, Kartik Paigwar, Xiang Fu, Donghyun Kim, Sangbae Kim, Pulkit Agrawal CoRL, 2021 paper / bibtex / project page Press: MIT News A hierarchical control framework for dynamic vision-aware locomotion. |
|
Yunzhu Li*, Shuang Li*, Vincent Sitzmann,Pulkit Agrawal, Antonio Torralba (*equal contribution) CoRL, 2021 (Oral) paper / website / bibtex Extreme viewpoint generalization via 3D representations based on Neural Radiance Fields. |
|
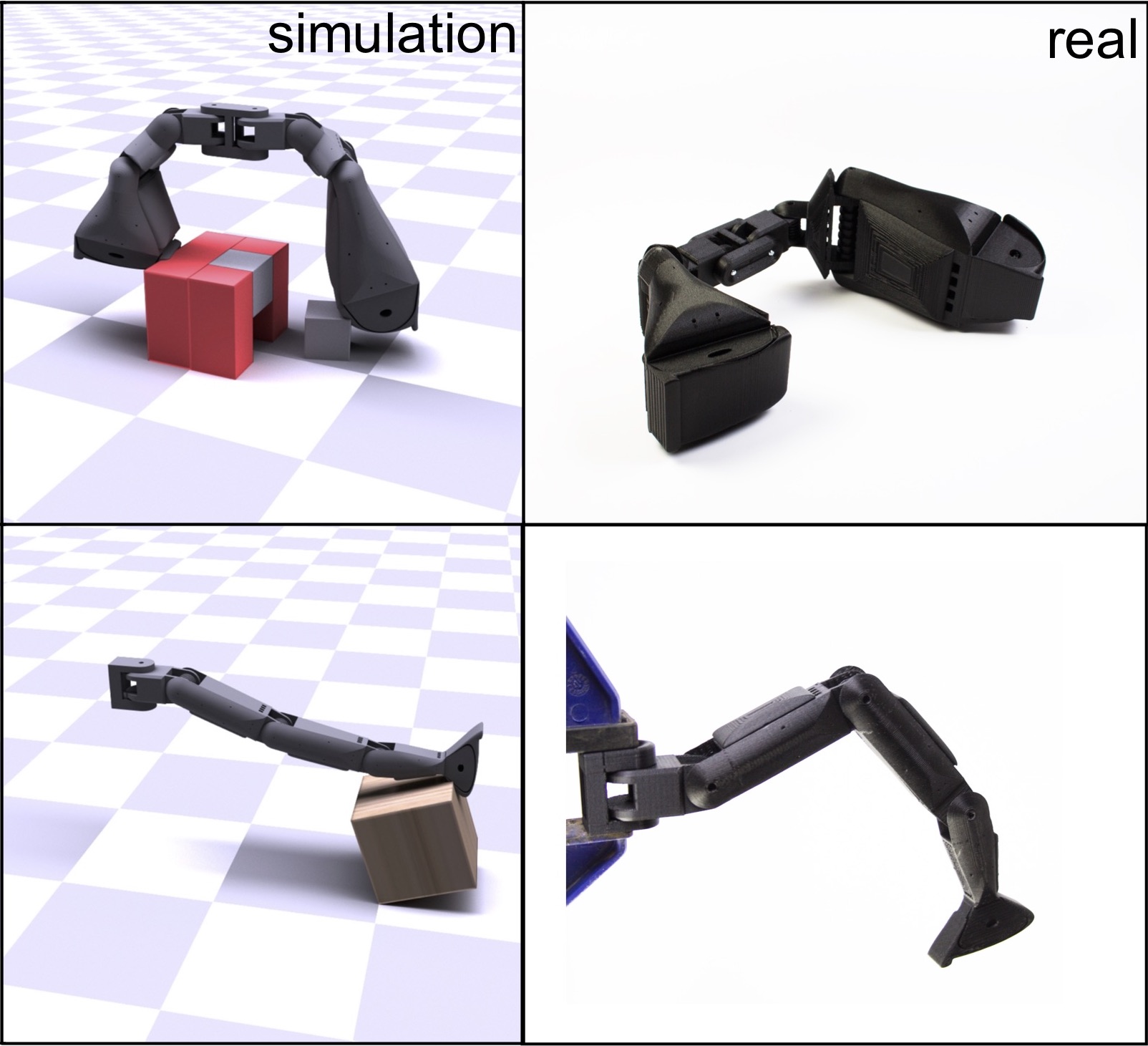
Jie Xu, Tao Chen, Lara Zlokapa, Michael Foshey, Wojciech Matusik, Shinjiro Sueda, Pulkit Agrawal RSS, 2021 paper / website / bibtex / video / Press: MIT News Computational method for design task-specific robotic hands. |

|
Xiang Fu, Ge Yang, Pulkit Agrawal, Tommi Jaakkola ICML, 2021 paper / website / bibtex A MDP formulation that dissociates task relevant and irrelevant information. |
|
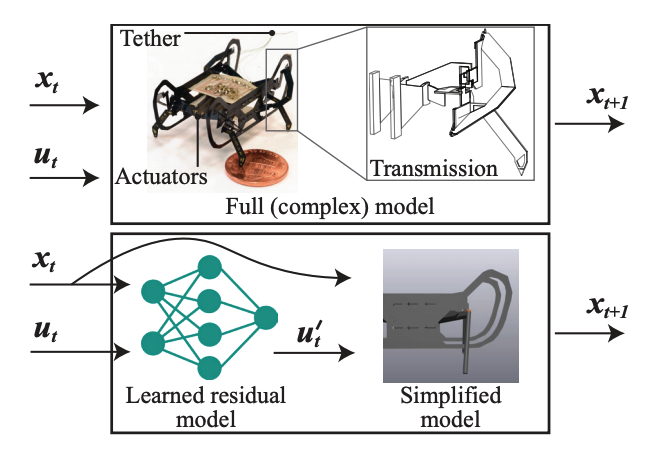
Joshua Gruenstein, Tao Chen, Neel Doshi, Pulkit Agrawal ICRA, 2021 paper / bibtex Data efficient learning method for controlling microrobots. |

|
Anurag Ajay, Aviral Kumar, Pulkit Agrawal, Sergey Levine, Ofir Nachum ICLR, 2021 paper / website / bibtex Learning action primitives for data efficient online and offline RL. |
|
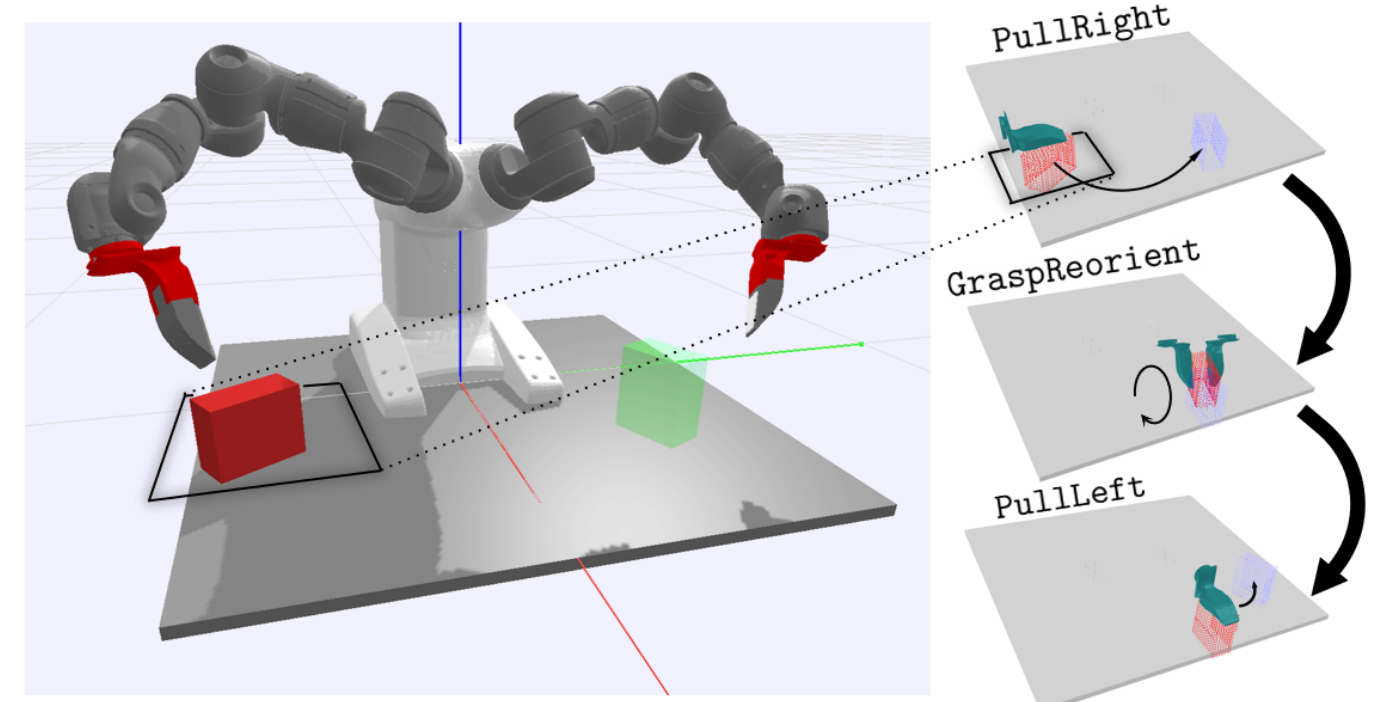
Anthony Simeonov, Yilun Du, Beomjoon Kim, Francois Hogan, Joshua Tenenbaum, Pulkit Agrawal, Alberto Rodriguez CoRL, 2020 paper / website / bibtex A framework that achieves the best of TAMP and robot-learning for manipulating rigid objects. |
|
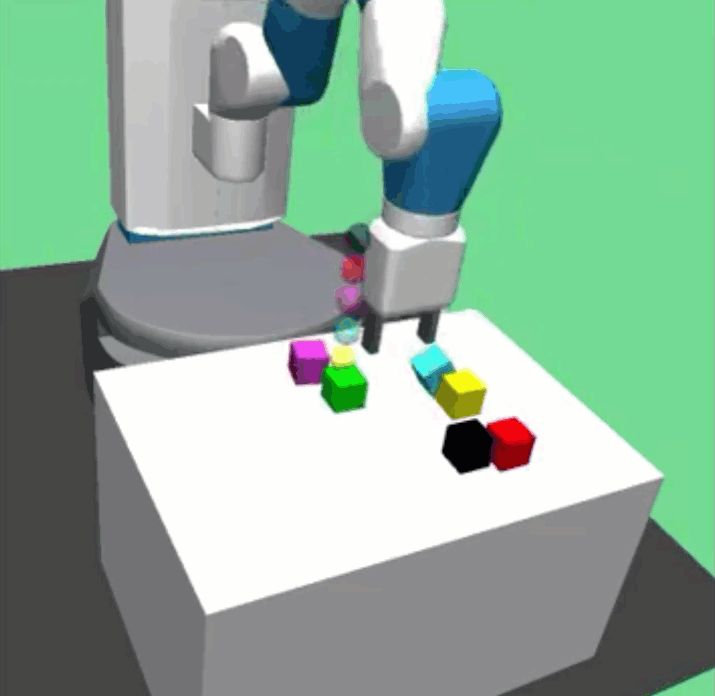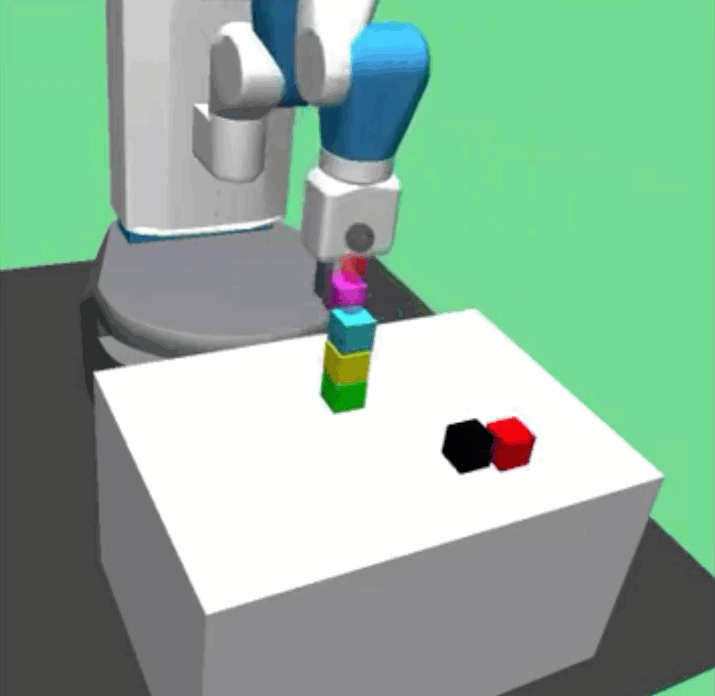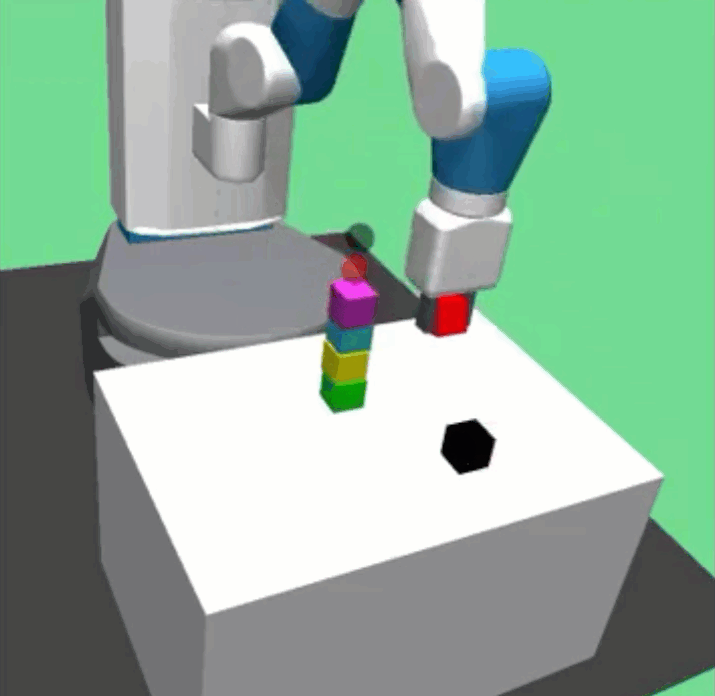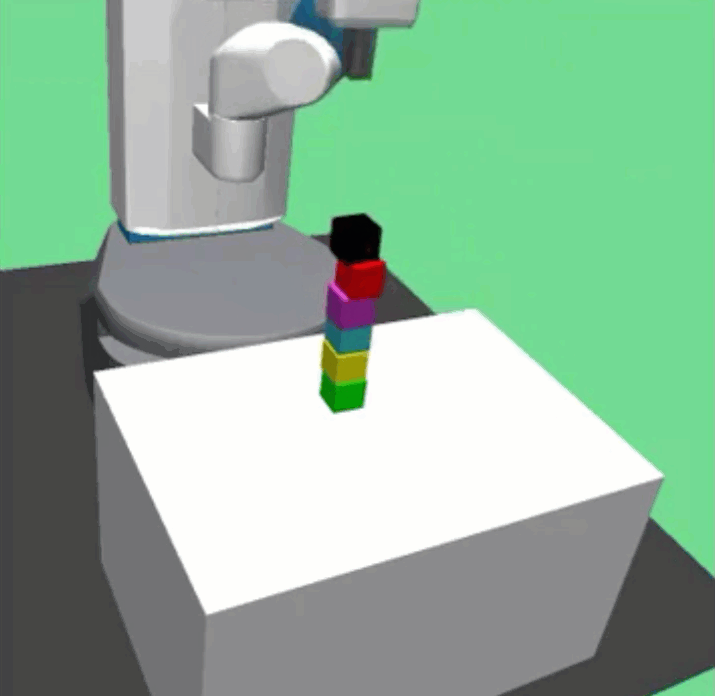
Richard Li, Allan Jabri, Trevor Darrell, Pulkit Agrawal ICRA, 2020 paper / website / code / bibtex Combining graph neural networks with curriculum learning for solve long horizon multi-object manipulation tasks. |
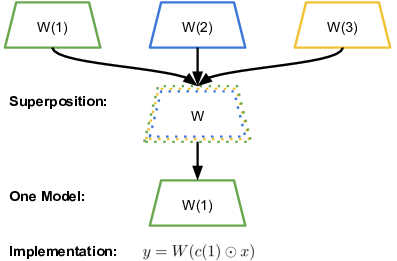
|
Brian Cheung, Alex Terekhov, Yubei Chen, Pulkit Agrawal, Bruno Olshausen, NeurIPS, 2019 arxiv / video tutorial / code / bibtex A method for storing multiple neural network models for different tasks into a single neural network. |
|
Glen L Xiong, Eleonore Bayen, Shirley Nickels, Raghav Subramaniam, Pulkit Agrawal, Julien Jacquemot, Alexandre M Bayen, Bruce Miller, George Netscher American Journal of Managed Care , 2019 paper / SafelyYou / bibtex Computer Vision based Fall Detection system reduces number of falls and emergency room visits in people with Dementia. |

|
Deepak Pathak*, Parsa Mahmoudieh*, Michael Luo, Pulkit Agrawal*, Evan Shelhamer, Alexei A. Efros, Trevor Darrell (* equal contribution) ICLR, 2018 (Oral) paper / website / code / slides / bibtex Self-supervised learning of skills helps an agent imitate the task presented as a sequence of images. Forward consistency loss overcomes key challenges of inverse and forward models. |

|
Rachit Dubey, Pulkit Agrawal, Deepak Pathak, Alexei A. Efros, Tom Griffiths ICML, 2018 paper / website / youtube cover / media / bibtex An empirical study of various kinds of prior information used by humans to solve video games. Such priors make them significantly more sample efficient as compared to Deep Reinforcement Learning algorithms. |
|
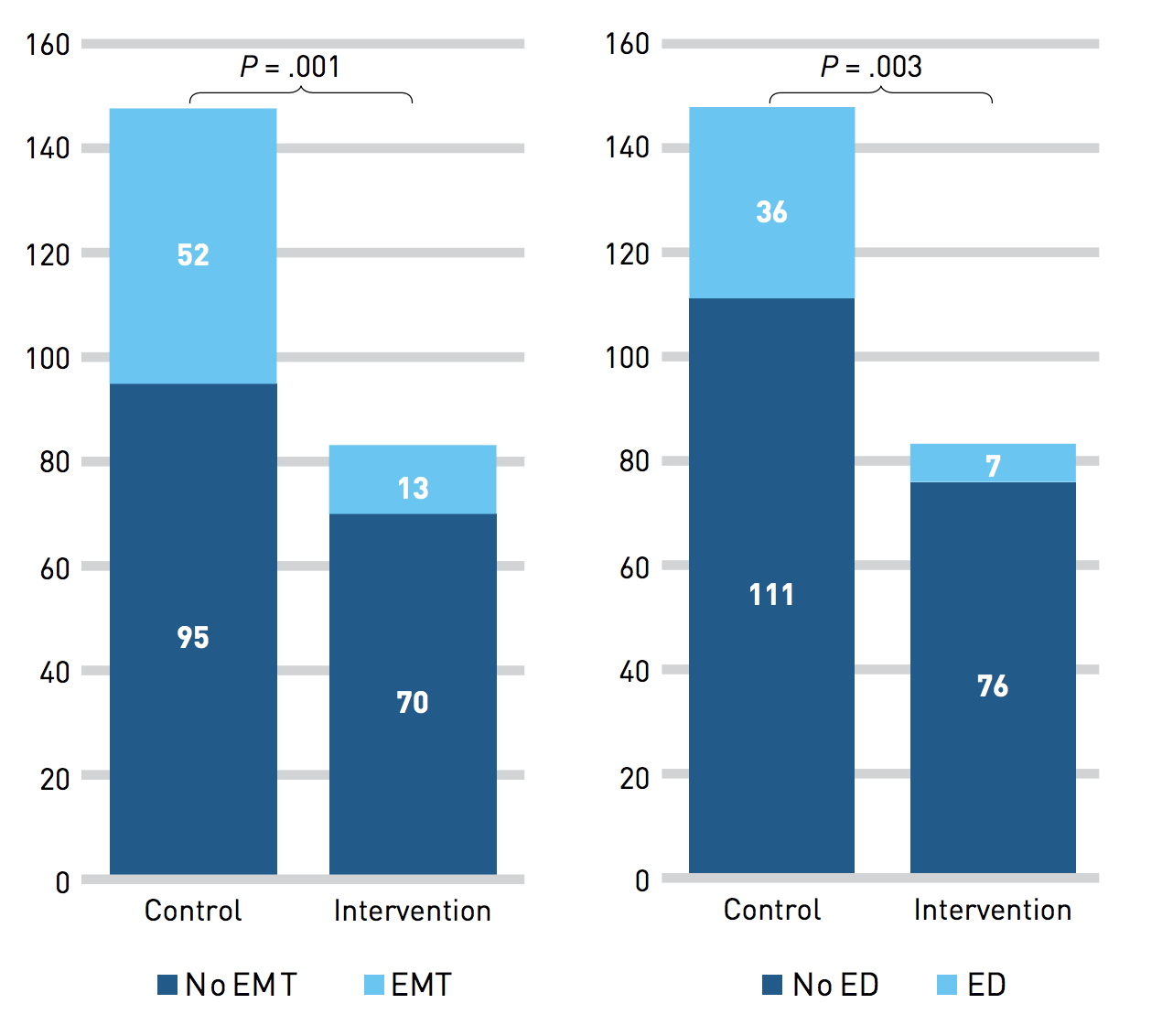
Deepak Pathak*, Yide Shentu*, Dian Chen*, Pulkit Agrawal*, Trevor Darrell, Sergey Levine, Jitendra Malik (*equal contribution) CVPR Workshop, 2018 paper / website bibtex A self-supervised method for learning to segment objects by interacting with them. |
|
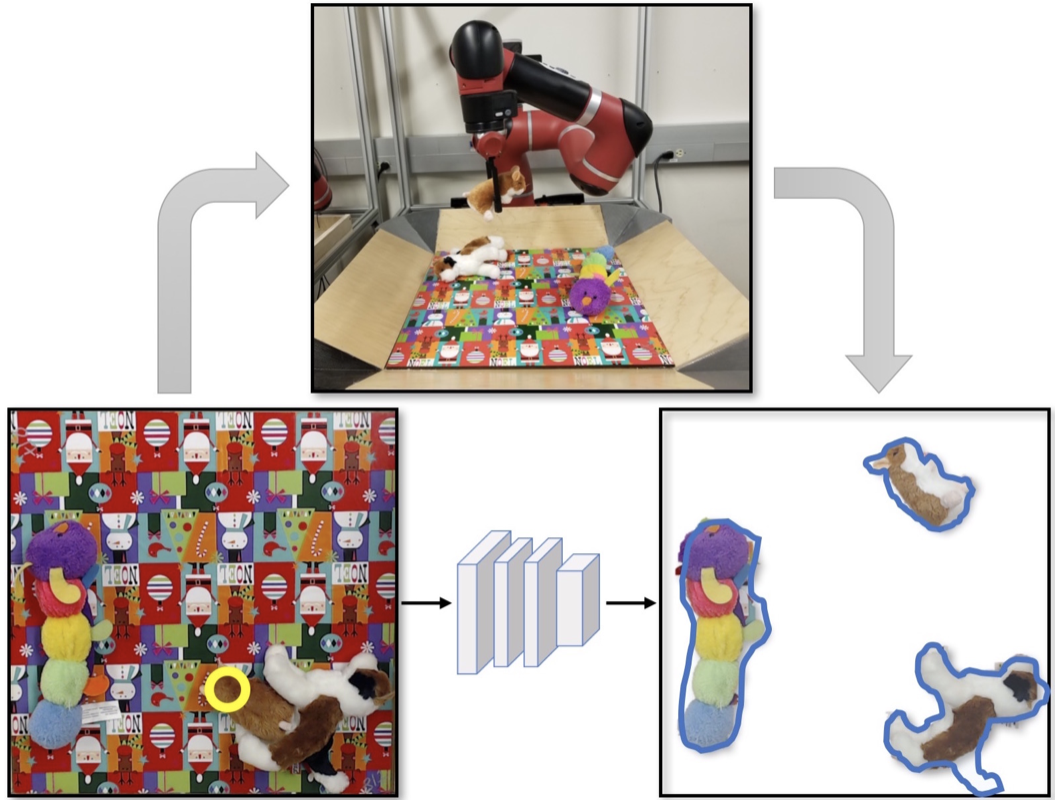
Jeffrey Zhang, Sravani Gajjala, Pulkit Agrawal, Geoffrey H Tison, Laura A Hallock, Lauren Beussink-Nelson, Mats H Lassen, Eugene Fan, Mandar A Aras, ChaRandle Jordan, Kirsten E Fleischmann, Michelle Melisko, Atif Qasim, Sanjiv J Shah, Ruzena Bajcsy, Rahul C Deo Circulation, 2018 paper / arxiv / bibtex Computer vision method for building fully automated and scalable analysis pipeline for echocardiogram interpretation. |

|
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, Trevor Darrell ICML, 2017 arxiv / video / talk / code / project website / bibtex Intrinsic curiosity of agents enables them to learn useful and generalizable skills without any rewards from the environment. |

|
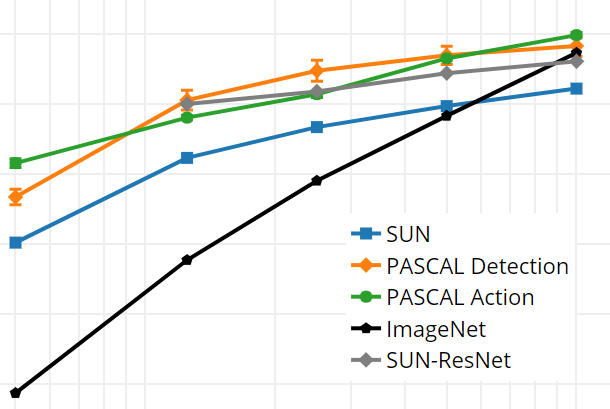
Panna Felsen, Pulkit Agrawal, Jitendra Malik ICCV, 2017 paper / bibtex Feature learning by making use of an agent's knowledge of its motion. |

|
Ashvin Nair*, Dian Chen*, Pulkit Agrawal*, Phillip Isola, Pieter Abbeel, Jitendra Malik, Sergey Levine (*equal contribution) ICRA, 2017 arxiv / website / video / bibtex Self-supervised learning of low-level skills enables a robot to follow a high-level plan specified by a single video demonstration. The code for the paper Zero Shot Visual Imitation subsumes this project's code release. |
|
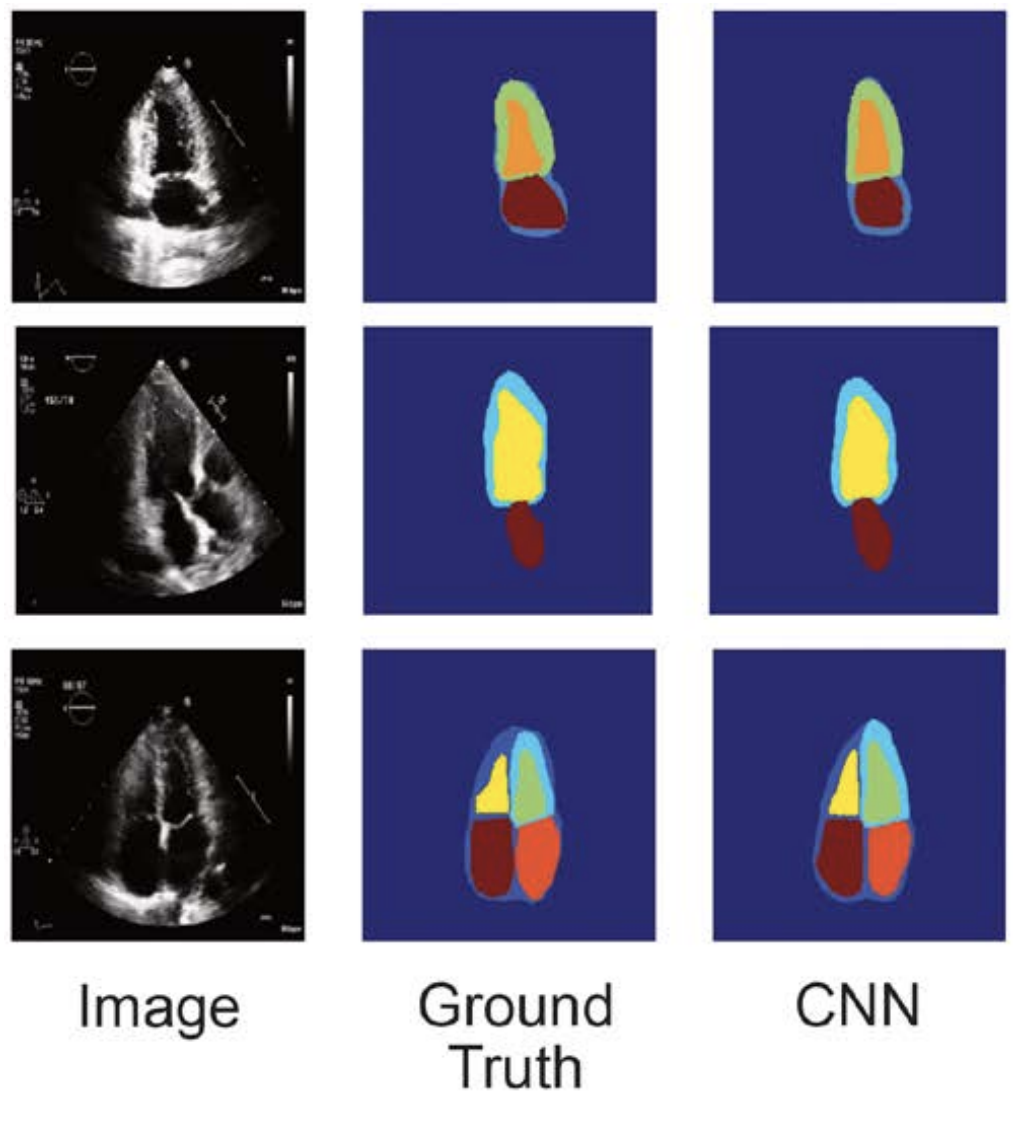
Misha Denil, Pulkit Agrawal*, Tejas D Kulkarni, Tom Erez, Peter Battaglia, Nando de Freitas ICLR, 2017 arxiv / media / video / bibtex Deep reinforcement learning can equip an agent with the ability to perform experiments for inferring physical quanities of interest. |
|
Eleonore Bayen, Julien Jacquemot, George Netscher, Pulkit Agrawal, Lynn Tabb Noyce, Alexandre Bayen Journal of Medical Internet Research, 2017 paper / bibtex Analysis how continuous video monitoring and review of falls of individuals with dementia can support better quality of care. |

|
Joao Carreira, Pulkit Agrawal, Katerina Fragkiadaki, Jitendra Malik CVPR, 2016 (Spotlight) arxiv / code / bibtex Iterative Error Feedback (IEF) is a self-correcting model that progressively changes an initial solution by feeding back error predictions. In contrast to feedforward CNNs that only capture structure in inputs, IEF captures structure in both the space of inputs and outputs. |

|
Pulkit Agrawal*, Ashvin Nair*, Pieter Abbeel, Jitendra Malik, Sergey Levine (*equal contribution) NIPS, 2016, (Oral) arxiv / talk / project website / data / bibtex Robot learns how to push objects to target locations by conducting a large number of pushing experiments. The code for the paper Zero Shot Visual Imitation subsumes this project's code release. |
|
Jacob Huh , Pulkit Agrawal, Alexei A. Efros NIPS LSCVS Workshop, 2016, (Oral) arxiv / project website / code / bibtex An empirical investigation into various factors related to the statistics of Imagenet dataset that result in transferrable features. |

|
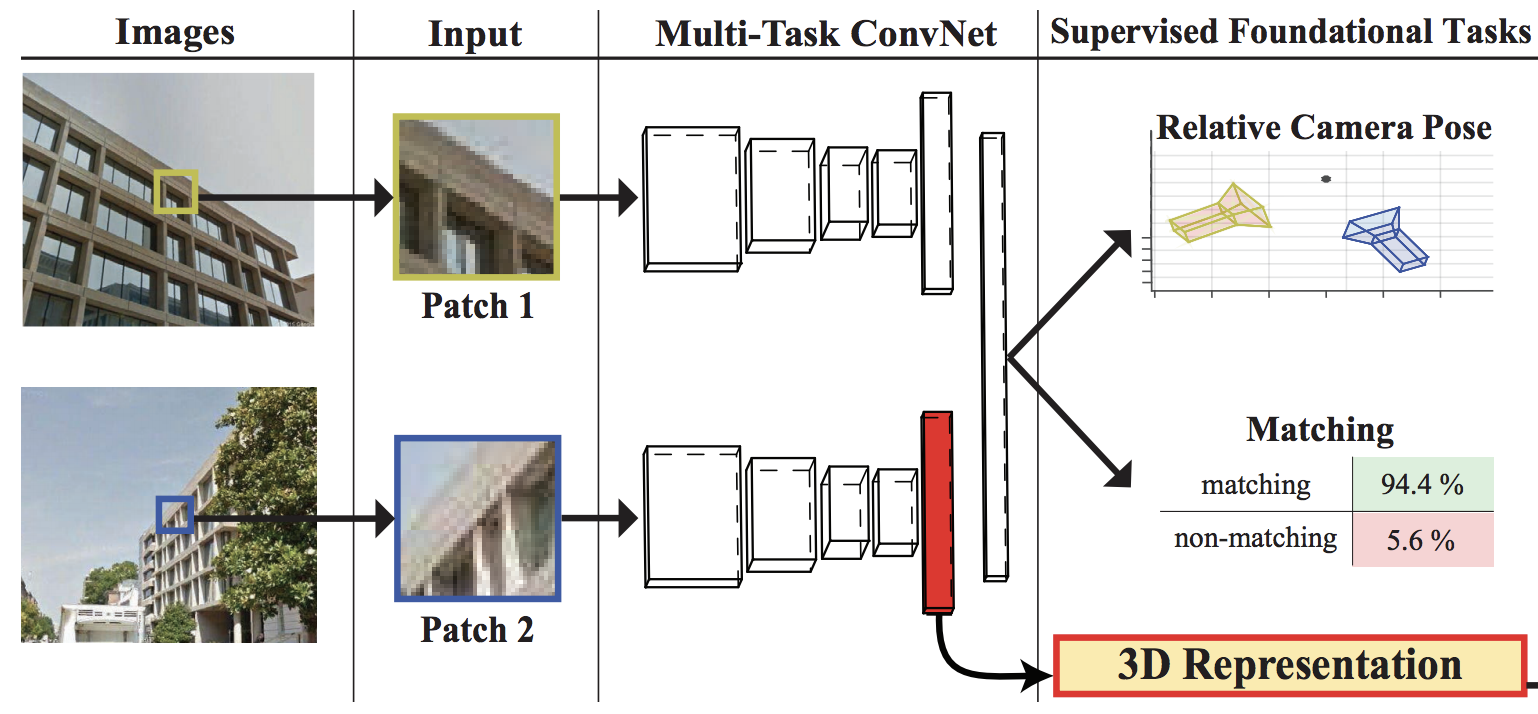
Katerina Fragkiadaki*, Pulkit Agrawal*, Sergey Levine, Jitendra Malik (*equal contribution) ICLR, 2016 arxiv / code / bibtex This work explores how an agent can be equipped with an internal model of the dynamics of the external world, and how it can use this model to plan novel actions by running multiple internal simulations (“visual imagination”). |
|
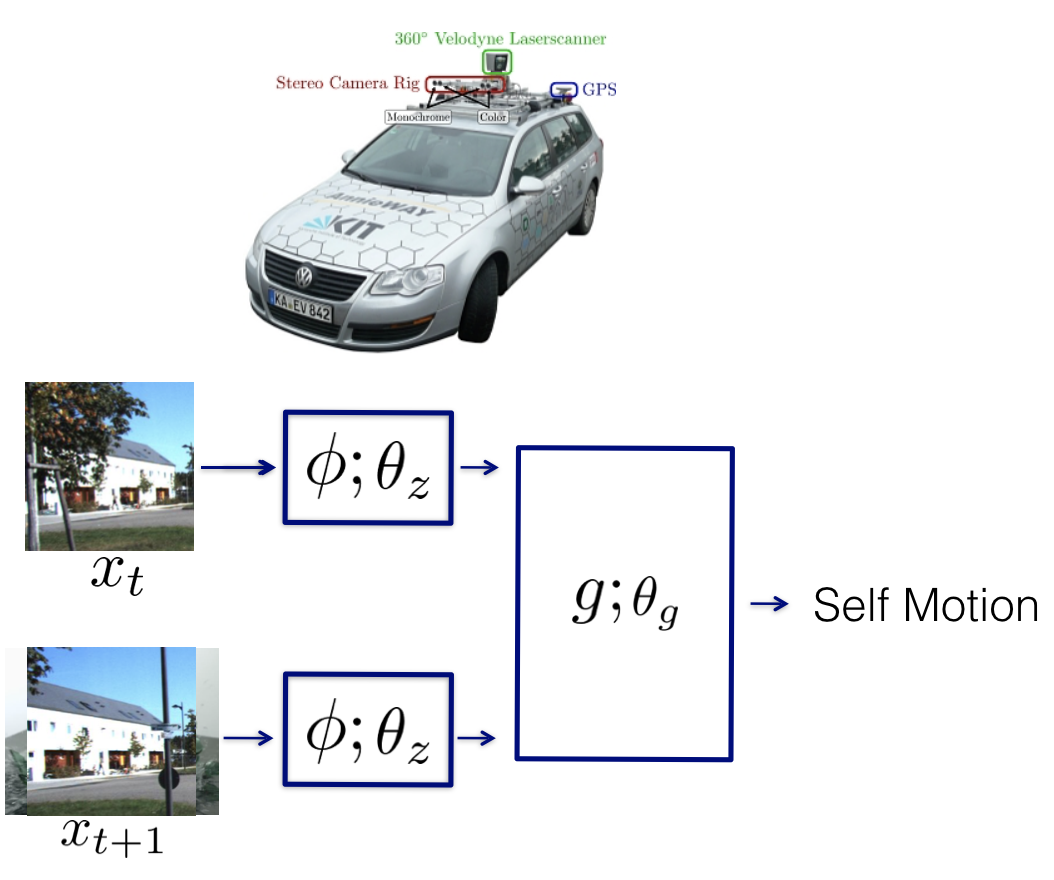
Amir R. Zamir, Tilman Wekel, Pulkit Agrawal, Colin Weil, Jitendra Malik, Silvio Savarese ECCV, 2016 arxiv / website / dataset / code / bibtex Large-scale study of feature learning using agent's knowledge of its motion. This paper extends our ICCV 2015 paper. |
|
Pulkit Agrawal, Joao Carreira, Jitendra Malik ICCV, 2015 arxiv / code / bibtex Feature learning by making use of an agent's knowledge of its motion. |

|
Pulkit Agrawal, Ross Girshick, Jitendra Malik ECCV, 2014 arxiv / bibtex A detailed study of how to finetune neural networks and the nature of the learned representations. |
|
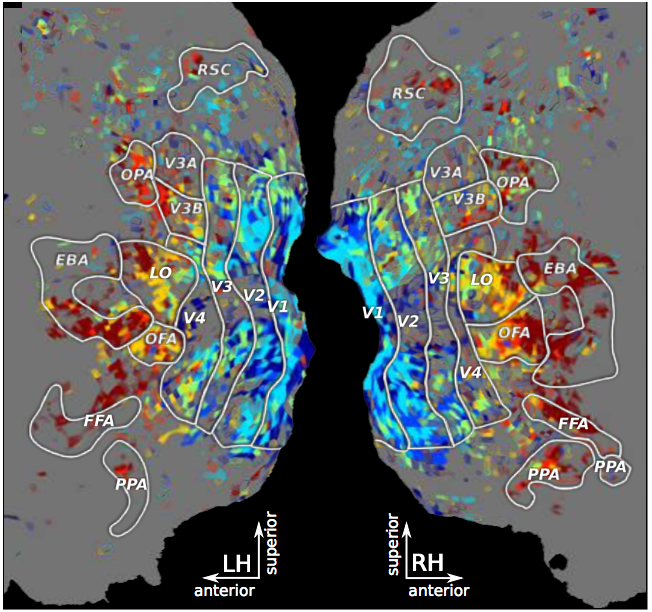
Pulkit Agrawal, Dustin Stansbury, Jitendra Malik, Jack Gallant (*equal contribution) arXiv, 2014 arxiv / unpublished results / bibtex Comparing the representations learnt by a Deep Neural Network optimized for object recognition against the human brain. |
|
Gahgene Gweon, Pulkit Agrawal, Mikesh Udani, Bhiksha Raj, Carolyn Rose Computer Supported Collaborative Learning , 2011 (Best Student Paper Award) arxiv / bibtex Method for identifying important parts of a group conversation directly from speech data. |
|
|
|
George Netscher, Julien Jacquemot, Pulkit Agrawal, Alexandre Bayen US Patent: US20190287376A1, 2019 |
|
Pulkit Agrawal, Somdeb Majumdar, Vikram Gupta US Patent: US20150278628A1, 2015 |
|
Pulkit Agrawal, Somdeb Majumdar US Patent: US20150278641A1, 2015 |
|
|
|
Program Chair, CoRL, 2024 Area Chair, ICML, 2021 Area Chair, ICLR, 2021 Area Chair, NeurIPS, 2020 Area Chair, CoRL, 2020, 2019 Reviewer for CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, RSS, ICRA, IJRR, IJCV, IEEE RA-L, TPAMI etc. |
|
|
|
Laurence Willement , PosDoc, now at TU Delft. Zhang-wei Hong , PhD 2025, now at IBM. Aviv Netanyahu , PhD 2025, now at a Stealth AI Startup. Tao Chen, PhD 2024, co-founded DexMate. Anurag Ajay , PhD 2024, now at Google. Ruben Castro , MS 2024. Jacob Huh , PhD 2024, now at OpenAI. Anthony Simeonov , PhD 2024, now at Boston Dynamics. Xiang Fu , PhD 2024. Bipasha Sen dropped out, co-founded Tangible. Brian Cheung Andrew Jenkins, MEng, 2024, now at Zoosk Srinath Mahankali, BS 2025, now at a Stealth Startup Jagdeep Bhatia, MEng 2025, now a Ph.D. student at UC Berkeley Arthur Hu, BS 2026 Gregory Pylypovych, BS 2025 Lars Ankile, MS 2025, now a Ph.D. student at Stanford. Tifanny Portela, visiting student 2023, now a Ph.D. student at ETH Zurich. Yandong Ji, visiting researcher 2023, now a Ph.D. student at UCSD. Meenal Parakh, MEng 2023, now PhD student at Princeton. Marcel Torne, MS 2023, now PhD student at Stanford. Alisha Fong, MEng, 2023 Alina Sarmiento, Undergraduate, 2023, now PhD student at CMU. Sathwik Karnik, Shreya Kumar, Yaosheng Xu, Bhavya Agrawalla, April Chan, Andrei Spiride, April Chan, Calvin Zhang, Abhaya Ravikumar, Alex Hu, Isabel Sperandino Andi Peng, MS 2023, now PhD student with Julie Shah. Steven Li , visiting researcher 2023, now a PhD student at TU Darmstadt. Abhishek Gupta, PostDoc, now Faculty at University of Washington. Lara Zlokapa, MEng, 2022 Haokuan Luo, MEng, 2022 (now at Hudson River Trading) Albert Yue, MEng, 2022 (now at Hudson River Trading) Matthew Stallone, MEng, 2022 Eric Chen, MEng, 2021 (now at Aurora) Joshua Gruenstein, 2021 (now CEO Tutor Intelligence) Alon Z. Kosowsky-Sachs, 2021 (now CTO Tutor Intelligence) Avery Lamp (now at stealth startup) Sanja Simonkovj, 2021 (Masters Student) Oran Luzon, 2021 (Undergraduate Researcher) Blake Tickell, 2020 (Visiting Researcher) Ishani Thakur, 2020 (Undergraduate Researcher) |
|
|